Medallion Architecture for AI in Enterprise Ecommerce: When It Helps and Why It Matters for Data Control

Your enterprise ecommerce platform is the core of your business, and the demands on it keep growing: analytics, operations, and now AI. All these systems rely on the same data inside your ecosystem, and if that data is fragmented and constantly changing, it triggers a cascade of broken metrics and a fundamental loss of data trust across your teams.
To break this cycle, enterprise teams can turn to medallion architecture—an approach that tames this chaos by progressively filtering data into raw, refined, and business-ready layers.
Rather than acting as a strict, step-by-step system, this method serves as a flexible framework whose fundamentals can be adapted to your specific system architecture. Based on our experience working with global enterprise clients, this article explores what those fundamentals include, where the model fits within enterprise ecommerce, and how it supports stable analytics and AI without requiring a full rebuild of existing systems.
Quick Tips for Busy People
For those short on time, here are the main points you need to know:
- A layered data design pattern: medallion architecture organizes data into three distinct tiers — bronze, silver, and gold — with each progressive layer adding refinement, structure, and business meaning.
- Each layer has a clear role: the bronze layer captures raw inputs untouched, silver unifies them into clean canonical entities, and gold reshapes those entities into custom, use-case-specific views.
- The benefits of medallion architecture appear in complex setups: the architecture becomes necessary when fragmented source systems, conflicting definitions, and frequent schema changes begin breaking downstream analytics and AI features.
- A natural fit for retail complexity: enterprise ecommerce is the ideal candidate for this model because its data is inherently scattered across disconnected platforms like PIM, ERP, and OMS.
- A reusable foundation for scaling: a shared silver layer prevents teams from building duplicate, isolated pipelines every time a new AI or analytics use case is introduced.
- A strategic choice based on scale: choose this architecture if you integrate at least three operational systems for multiple consumers; skip it if your data estate is small and your priority is the lowest immediate complexity.
With an understanding of these core concepts, let’s look at them in detail.
What Is Medallion Architecture?
In plain terms, medallion architecture is a data design pattern that processes information through three named layers: bronze, silver, and gold, with each layer adding more refinement, structure, and business meaning than the one before it.
The term medallion data architecture refers to the same approach, and it’s most associated with the lakehouse model popularized by Databricks, but the principles travel well beyond any single tool or vendor. How an enterprise structures this underlying data pipeline directly dictates the success of its high-stakes digital initiatives.
According to McKinsey’s State of AI research, 88% of organizations now use AI in at least one business function, yet only 39% report any enterprise-level EBIT impact, and most of them say AI accounts for less than 5% of EBIT. It shows that adoption is universal, but value capture is rare.
The reasons vary, but a recurring one, and the one medallion architecture is built to address, is the data foundation underneath the model. To close this value gap, the framework systematically upgrades data quality across three distinct operational phases.
The bronze layer holds raw data exactly as it lands from the source. The silver layer cleans, normalizes and obfuscates if needed, and stitches that data into consistent shapes. The gold layer may contain multiple sets of data targeted for different purposes: analytics, AI knowledge base, data mart, ML training data, etc. We’ll unpack each layer next.
What matters here is that the model gives you more control as data moves from messy ingestion to a state your AI systems and downstream consumers can trust and use. The approach is especially useful in large-scale enterprise systems, as it helps avoid the common situation where multiple teams build their own pipelines for various use cases, eliminating the risk of fragmented, conflicting data definitions across your core business operations.
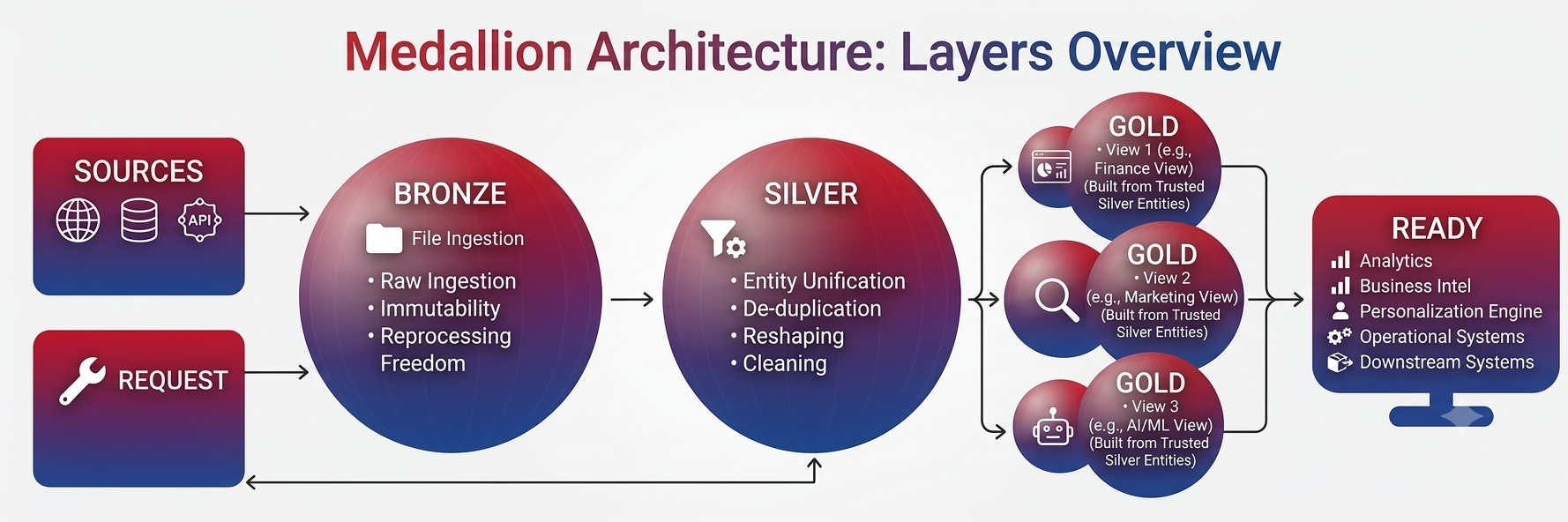
Medallion Architecture: Layers Overview
Each layer handles one stage of turning raw source data into consumption-ready data. Bronze captures the raw input as it arrives, silver cleans and unifies it into consistent entities, and gold prepares those entities into views built for specific consumers, such as analytics, search, or AI.
Bronze layer
The bronze layer in medallion architecture is the raw ingestion layer, where data is stored exactly as it arrives from each source system, with no cleanup, reshaping, or merging applied.
The value of keeping data untouched at this stage is that your source systems can keep delivering data the way they always have. Ingestion is completely database-agnostic and fast, allowing teams to deploy dumps, change data capture (CDC), or real-time event streaming within minutes across diverse sources, ranging from Oracle, MongoDB, and Cassandra to flat Excel sheets and raw S3 buckets — all into a single location.
You don’t need to renegotiate schemas with the PIM team, force the ERP to align with the storefront, or run a multi-year project to standardize how every system emits its data, all of which is expensive, slow, and rarely achievable at enterprise scale. The work of making that data AI-ready, analytics-ready, or operations-ready happens downstream in silver and gold, not at the source.
This also gives you reprocessing freedom: if a downstream rule changes or a bug needs replaying against historical data, you can rerun transformations from bronze without re-pulling from the source. Lineage and auditability are maintained here too, so every refined number in your gold layer can be traced back to the exact bronze record it came from.
Silver layer
The silver layer is the transformation layer of medallion architecture, where raw data from bronze is cleaned, deduplicated, and reshaped into consistent, well-structured entities that downstream consumers can rely on. Currencies, units, identifiers, and category labels are unified across feeds so the same concept stops appearing in multiple conflicting forms.
Where it makes sense, silver also enriches: a product record might pick up the canonical brand name, a customer event might gain a stable customer ID after identity resolution, or an order might be tagged with the correct fulfillment region.
Structurally, the silver layer remains plain and normalized: modeled closer to a clean fact-dimension schema with minimal complex relations kept. The aim is reusable and well-shaped entities that any downstream team can rely on without redoing the cleanup themselves. This simplified design directly prevents overengineering during partial data updates and recalculations.
The silver layer is where most of the engineering discipline and a lot of the internal debates happen. If you get silver right, the gold layer becomes a fast presentation step. If you get it wrong, dashboards disagree on basic metrics, AI features train on inconsistent inputs, and every downstream team rebuilds cleanup logic locally to compensate.
Gold layer
The gold layer medallion architecture is the consumption layer, where data from silver is reshaped into use-case-specific views that are ready for analytics, search, AI, and operational systems to consume directly. Each view is tuned to a specific consumer and built from the same trusted silver entities, so the underlying data stays consistent even when the presentation differs.
The important nuance is that there is rarely just one gold view. A merchandising dashboard, a personalization engine, a customer service co-pilot, and a financial close all need different shapes of the same underlying data.
Gold is where you build these consumption-aligned views in parallel, each tuned to its consumer, and sourced from the same trusted silver layer. These parallel views can operate on entirely different update cadences. This flexibility helps manage internal and external data provision, handle independent data release cycles, and meet distinct SLAs with different downstream clients.
This layer is where the value becomes visible. If bronze and silver are infrastructure work, gold is what your stakeholders see, click, and base decisions on.
Get a practical approach that you can apply to your platform.
Download the guideWhen to Use Medallion Architecture
Medallion architecture is highly effective when you need a unified and prepared data foundation for various use cases, including AI implementation. This necessity typically arises from fragmented data scenarios common in enterprise ecommerce.
-

Data comes from multiple operational systems
When orders, products, inventory, customers, and pricing exist in their own system with their own update cadence, you need a place that can ingest all of them without forcing source-level standardization. Bronze handles it.
-

The same entity is represented differently across sources
Without global identity resolution, individual systems act as isolated islands of truth. For example, a "client" has one set of IDs in your CRM and an entirely different, unlinked set in shipment management. Silver’s job is to map these conflicting identifiers and merge them into a single entity. This settles the structural disagreement once, preventing downstream teams from having to manually reconcile data in every single report.
-

Downstream teams need analytics, search, AI, or reporting from the same data estate
When the same underlying records have to feed dashboards, recommendation models, internal tooling, and finance, you can't afford to keep bolting one-off pipelines onto raw sources. Gold gives each consumer its own tuned view from a shared base. Without it, you need to maintain a parallel pipeline per use case.
-

Small source changes keep breaking downstream consumers
A renamed field in PIM, a new currency code in the storefront, or an extra tax line on a payment provider can cascade into broken dashboards and failed AI features. The layered model contains the breaks: silver absorbs the upstream shape change, and downstream consumers stay stable.
-

Teams need lineage, reproducibility, and clearer ownership
Auditors, compliance teams, and AI governance reviewers regularly require evidence of how a specific value in a dashboard or AI output was derived, and the layered structure of medallion architecture provides that by design. Every transformation between bronze, silver, and gold is documented and reversible, so any output can be traced back to the source record it came from.
What ties these signals together is that they are not isolated issues but recurring patterns in how enterprise commerce data behaves, and once they start to stack, the need for a structured approach becomes hard to ignore. This is where the medallion model starts to look like a practical way to bring order to what is already happening across systems.
The broader data and AI landscape points in the same direction. Gartner predicts that during 2026, organizations will abandon 60% of AI projects if those projects are not supported by AI-ready data. Databricks usage data reinforces this shift from the infrastructure side, with data integration growing 117% year over year and 61% of customers moving toward lakehouse architectures.
Together, these trends point to a broader industry shift toward structured data foundations as a prerequisite for AI and analytics at scale, and enterprise ecommerce is one of the environments where this shift applies most directly.
Medallion Architecture in Enterprise Ecommerce
Enterprise ecommerce is a strong fit for medallion architecture because three of its defining traits, including fragmented source systems, diverse downstream consumers, and constant schema drift, are the exact conditions the layered model is built to handle. The same traits are also what determine whether AI features built on commerce data perform reliably at scale, which is why the architecture has become a practical foundation for AI in this space.
Enterprise ecommerce data landscape
In practice, ecommerce data is spread across systems, with product catalogs in PIM, inventory and pricing in ERP, orders in OMS, and customer data across CDP, CRM, and marketing automation, while search, personalization, and analytics each rely on their own structures. When this is extended across markets, brands, and channels, it results in dozens of systems feeding the same business without a shared structure, which is the exact candidate for the medallion approach.
For traditional analytics and reporting, this fragmentation is manageable, if expensive. For AI features that depend on consistent, well-structured input, it becomes a direct blocker, because a model trained or retrieving against inconsistent entity definitions hallucinates and picks random data data sources. A layered approach addresses this by absorbing those differences in one place instead of requiring every system to stay aligned.
Our team has been designing layered data foundations for enterprise commerce platforms for years across PIM, OMS, ERP, and AI consumption layers.
Let’s TalkEnsuring control, traceability, and governance
Working with data on silver and gold layers, you also make three things easier:
- Traceability improves: every transformation is documented and reversible back to bronze. For AI specifically, model training and fine-tuning are often built on patterns like MLflow that include data source versioning. Combining this with a medallion architecture guarantees a reproducible dataset mapped to the moment it was consumed by the model. This means you can prove where training data originated, which silver entities a retrieval system queried, and how a specific AI output was derived.
- Transformation logic becomes clearer: it is centralized in one place. AI teams stop maintaining their own parallel cleanup pipelines, and any change to how a product, customer, or order is defined propagates to every model and feature consuming that entity.
- Governance becomes practical: consumption happens through prepared views, which means you can apply policy, masking, and access control at the gold layer instead of chasing every raw source. The same mechanism extends to AI: sensitive fields can be excluded from AI-facing gold views without restructuring the underlying data, and access to AI-ready datasets can be managed centrally.
This is also what makes the architecture friendly to platform owners who are accountable for both speed and control. You’re not slowing teams down with a central data team gating every request, you’re giving them a stable foundation they can self-serve from.
Support for multiple ecommerce scenarios
The same medallion-prepared data foundation can support very different scenarios, and the diversity of consumers is one of the main reasons enterprise commerce platforms benefit from the model.
AI is where this matters most, because AI features rarely arrive one at a time. A platform that adds a product recommendation model this quarter is often adding a semantic search experience, a customer service co-pilot, a demand forecasting model, and a fraud detection layer over the next 18 months, and each one needs the same underlying product, customer, and order data in a different shape.
Without a shared silver layer to read from, each AI use case builds its own cleanup pipeline against raw operational data, and the platform ends up with five parallel implementations of “what a product is.”
Move beyond one-off AI tools and design a foundation that can scale across your business without constant rework. Download the whitepaper to get a clear path to building an AI core that holds up as you grow.
At this point, the architecture becomes easier to understand through a concrete example, especially when you look at how it supports a specific AI use case.
Enterprise Ecommerce Example of Medallion Architecture
Adding AI search to a commerce platform is one of the easier AI projects to start, but it can easily result in inconsistent results, out-of-stock products, or wrong prices (e.g., a wrong sales channel selected). The cause is usually all those problems described earlier in the article: fragmented and inconsistent data that AI search relies on. Let’s take a look at how the medallion approach can address this.
-
Bronze
Product feeds, inventory updates, content snippets, customer reviews, and category metadata land from each source system into a raw zone. Original payloads are preserved with metadata about source, timestamp, and ingestion method, and no merging, deduplication, or reshaping has taken place.
-
Silver
Product records are deduplicated across feeds and attribute names are unified across markets ("color" / "colour" / "shade" all become one canonical field). To ensure the search engine has deep technical data to query, this layer executes attribute enrichment, automatically pulling structural data from the PIM and matching SKUs against supplier documentation to fill in missing product specifications. Full-text fields undergo normalization: titles are standardized and raw product descriptions are processed into clean, noise-free text blocks optimized for tokenization. Categories are reconciled into a single taxonomy, reviews are linked to the correct product IDs, and inventory and pricing data are joined to the canonical record. As a result, each item is represented as one clean, enriched, and well-structured product entity, regardless of how many raw sources contributed to it.
-

Gold
The AI use case gets its own gold view: product records shaped for embedding generation, with the specific fields the retrieval model needs, in the structure it expects. But this data can be used for other views as well, all reading from the same silver layer.
The AI feature behaves predictably because it’s reading from data that has been deliberately prepared for AI, not from raw catalog feeds it has to interpret on the fly. When a new market or a new feed gets added, the change is absorbed in silver, and the AI gold view stays stable. The model’s performance improves because the underlying data becomes consistent and controlled.
This is the principle behind the AI Search Readiness Kit solution — a packaged version of this layered approach for ecommerce platforms looking to make their product data AI-ready without restructuring their entire stack.
When to Choose Medallion Architecture
Choose medallion architecture when your data spans multiple systems, your downstream consumers are diverse, and their stability matters more than the cost of the layered approach. That’s the short version. The longer answer depends on what you’re optimizing for.
It’s a strong fit when:
- You have many sources feeding many consumers, and the matrix between them is growing.
- You need lineage, governance, and reproducibility for compliance, audit, or AI risk reviews.
- You want to add AI, advanced search, or analytics on top of operational data without destabilizing the operational systems.
- Different teams and clients need different shapes of the same underlying data.
It’s not the right fit when:
- Your data estate is small and limited to one or two sources. A leaner pipeline is usually sufficient, and introducing a full three-layer architecture can add unnecessary complexity without proportional value.
- All data needed by your consumers is unified and kept within a single database.
- Your priority is the lowest possible operational complexity over the next 12 months, and you’re willing to accept the technical debt that comes with it.
Quick assessment — use medallion architecture if you can answer “yes” to most of these:
- Do you ingest data from at least three operational systems with their own update cadences?
- Do at least two distinct consumers (analytics, search, AI, operations, finance, etc.) need to read from that data?
- Have you had a downstream consumer break in the last six months because of an upstream schema change?
- Do you need to be able to trace any number in a dashboard back to its source record?
- Are you planning to ship AI features on top of operational data within the next 12 months?
Three or more “yes” answers, and the architecture is paying for itself the day you turn it on. Five out of five and you’re already living the medallion problem — you just haven’t given it a name yet.
To Sum Up
Medallion architecture provides a structured way to manage fragmented, multi-source data by separating ingestion, transformation, and consumption into distinct layers. This reduces instability from upstream changes, aligns definitions across teams, and supports multiple use cases without duplicating pipelines.
It also creates the conditions for more reliable AI and analytics, since models and downstream systems depend on consistent, traceable, and well-prepared data rather than raw inputs. The result is greater control, clearer ownership, and a data foundation that can evolve without constant rework.
The approach is most effective in environments with multiple systems and diverse consumers, where stability and consistency matter more than minimal setup. For simpler setups, a leaner pipeline may be sufficient.
If you’re thinking about how to structure your data as complexity grows, we’re available to talk through your setup.
FAQ
-
What is medallion architecture?
Medallion architecture is a layered data design pattern that processes information through three named tiers: bronze (raw ingestion), silver (cleaned and unified), and gold (consumption-ready views), with each layer adding more refinement and business meaning. It's most associated with lakehouse implementations, but the principles apply to any large enterprise data environment.
-
What is the difference between bronze, silver, and gold layers?
Bronze stores raw data exactly as it arrives, untouched, for replay and lineage. Silver cleans, deduplicates, and unifies the data into consistent canonical entities everyone can use. Gold reshapes the entities into specific views aligned with each consumer, including analytics, search, AI, and operations, so the business can use the data without redoing the cleanup.
-
When should I use medallion architecture?
Use medallion architecture when data flows in from multiple operational systems, downstream consumers need different shapes of the same data, and small upstream changes keep breaking downstream features. It's valuable when you need lineage and governance for compliance or AI risk reviews, or when you're planning to ship AI features on top of operational data.
-
How does medallion architecture help in ecommerce?
In enterprise ecommerce, medallion architecture stabilizes the data layer between fragmented operational systems (PIM, OMS, ERP, CDP, CRM) and the many consumers that depend on them (analytics, search, personalization, AI, finance). It absorbs upstream drift in the silver layer, prepares consumer-specific views in gold, and keeps everything traceable back to the original source, which is what makes AI features and analytics behave predictably at scale.
As Head of Technology Strategy and Solutions at Expert Soft, Andreas Kozachenko specializes in architectural strategy for complex enterprise ecommerce systems. His expertise in structuring layered data foundations helps global brands unify fragmented data, ensuring their platforms are stable and fully optimized for AI scaling.
New articles

See more

See more

See more

See more

See more
