Search Portal Transformation for a Leading Credit Rating Agency
Technologies: Java, Spring Boot, Kafka, Kubernetes, MongoDB, Solr, GraphQL, HATEOAS, EC2, Amazon S3
Client
Our client is a global credit-rating agency that delivers financial analytics to businesses and investors. Their platform provides subscribers with financial insights on industries and organizations, empowering businesses to assess investment risks, identify financial opportunities, and make well-informed decisions.
Need
The client turned to Expert Soft to split their existing data access and search portal into two distinct systems. The challenge was to restructure the existing data architecture while maintaining seamless search functionality across both new platforms.
Solution
The solution was built with microservices architecture, so the client was seeking a team with strong microservices architecture and development services. Expert Soft’s back-end developers stepped in, taking charge of the microservices responsible for alerts and data search. Our duties involved dividing a unified data structure into separate sets tailored for each portal. Along the way, we boosted application resilience and tackled several technical challenges.
Challenge 1. Data separation
For main data storage, the client leverages MongoDB. However, the search process takes place in the Solr — a search engine designed for full-text search. Solr acts as another storage optimized for search, independent from MongoDB.
The system works in the following way:
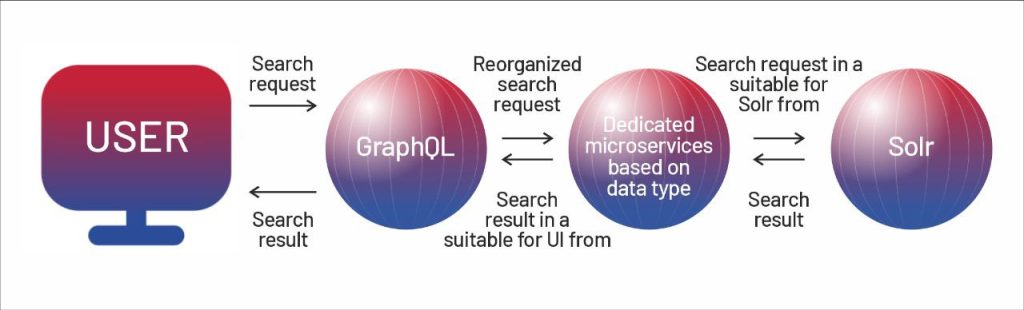
Our team had to restructure the data in both repositories to align with the needs of the two new platforms. This involved creating one-run migration scripts and categorizing data. We also introduced new REST API parameters to ensure that requests from each portal were served by the appropriate data sets.
Challenge 2. Increasing system resilience
To keep both MongoDB and Solr consistent, two synchronization mechanisms were in place. The system synchronized some data immediately upon entry, while other batches were processed later during regularly scheduled jobs.
Initially, background data synchronization was implemented synchronously: portions of data were sent via REST requests, and periodically some of them failed due to network issues or service unavailability. There was no automatic recovery from such failures and it caused a data loss.
To eliminate the issue, we switched to asynchronous communication using Kafka message brokers. This allowed us to queue failed messages and automatically reprocess them later. This way we ensure data consistency and eliminate the risk of data loss, enhancing the overall system stability.
Challenge 3. Software update
To enable efficient search infrastructure, the client relied on Fusion — a search platform built on top of Solr search engine with extended functionality. However, the Fusion version they were using was outdated, so we needed to migrate them from Fusion 4 to Fusion 5.
The challenge lay in the different data schemas, as Fusion 5 was not compatible with the indexes from Fusion 4. Re-indexing millions of records manually was too risky, so we ran both versions of Fusion in parallel for several months, feeding data into both systems to ensure consistency.
Once we verified the data integrity, we fully transitioned search functionality to Fusion 5, ensuring a smooth migration.
Microservices Best Practices
One notable microservices best practice in this project that simplified communication among microservices was HATEOAS (Hypermedia as the Engine of Application State). HATEOAS is a REST architecture principle that extends the capabilities of the REST API by inserting in response information about possible future actions with the resource.
In this project, HATEOAS was particularly helpful for handling large datasets and paginated data. Microservices designed to provide paginated data to other services included links to the next, previous, first, and last pages of data, which was handy for data loading.
While we didn’t develop this approach, we leveraged it effectively when working with microservices outside our direct control, demonstrating our ability to handle advanced REST maturity levels and strengthening the benefits of using microservices.
Results



