The Executive Guide to Planning Successful Legacy System Migration

Legacy platform migration is one of those projects everyone knows is necessary, but few are eager to start. It’s often complex, stressful, and full of pitfalls. I’ve seen migration plans postponed for years just because teams hoped to buy a little more time.
Meanwhile, layers of dependencies, tech debt, and stale data keep piling up. Workarounds multiply, integrations grow brittle, and what could have been a well-controlled transition slowly turns into a high-risk operation. And when, according to research, downtime can drain up to $9,000 per minute for large organizations, the pressure to get it right only intensifies.
That’s the purpose of this guide: to make sense of all the moving parts and show the bigger picture, rather than walk you through another dry checklist. The guide focuses on the real challenges of moving off legacy systems, including the hidden costs, the data traps, and the common mistakes that quietly derail progress.
I’ll share patterns to avoid and lessons learned from real migration projects our team at Expert Soft has delivered. By the end, you’ll have a grounded way to think about your own migration and the confidence to plan one that actually works.
Quick Tips for Busy People
If you don’t have time to dig into the full playbook, here are the essentials. These are the points we keep coming back to in legacy systems migration.
- Path choice: decide between migrate, modernize, or stabilize based on business criticality, change velocity, and integration brittleness, not habit.
- Strategy context: adapt your approach to geography, distributed teams, and release cadence. This alignment reduces risk and hidden costs.
- Safeguards before change: prevent downtime and data drift by verifying customer parity and defining rollback triggers in advance.
- Execution focus: monitor cutover risk, validate performance under real traffic, and ensure rollback readiness throughout deployment.
- Data program: treat data as its own workstream, covering discovery, cleansing, mapping, CDC, and reconciliation, to ensure accuracy and trust in every transaction.
- Parallel operation: run legacy and new systems side by side wherever revenue is exposed, as dual run is cheaper than downtime.
- Validation lens: track reliability, data quality, and business outcomes after go-live to confirm the new system delivers stable performance and measurable value.
Let’s get down to details.
Migrate vs. Modernize vs. “Leave As-Is”
Before diving into migration, it’s worth pausing to confirm it’s truly what your system needs. A full-scale migration to headless or a simple stabilization phase can ripple through revenue, compliance, and innovation.
Migration is the blunt play you choose when your current system has reached its technical limits. It often shows up in integrations breaking too often, scaling becoming costly, or security and compliance that no longer keep up. Modernization is the better route when the foundation is still solid, but the architecture or components need an upgrade to support new capabilities.
“Leave as-is” (stabilization) strategy makes sense when a system is low-risk, rarely changed, and still supported. It’s a practical pause, but only if you keep it secure, monitored, and tuned.
Below is a framework that helps weigh available options and find the path that fits a business best. Score each of these factors from one to five:
- Business criticality: what is the revenue/operational impact of downtime or degraded experience?
- Change velocity: how often does the domain change (daily, weekly, quarterly)?
- Integration fragility: how brittle are upstream/downstream interfaces (batch transfers, shared schemas, tight coupling)?
- Talent & support: do we have skills and vendor support for the next 3–5 years?
- Compliance pressure: are there regulatory deadlines or audit findings forcing change?
- Cost trajectory: will keeping the legacy system increase run costs (licenses, hardware, on‑call) faster than alternatives?
- Customer experience gap: are we competitively behind (speed, features, accessibility, SEO)?
- Risk appetite & rollback: can we tolerate staged rollouts and maintain parallel run if needed?
When certain factors consistently score highest, the direction becomes clearer. High criticality, high change, and brittle integrations point to modernizing incrementally with a parallel run. Low change, stable integrations, and compliance pressure call for a quick migration. A legacy system can then remain in place until a deeper redesign becomes viable. Low criticality, low change, and available talent make stabilization a sensible choice, as long as you keep investing in observability and security.
Is migration still the right path? Then, let’s move to the migration strategy.
Our team helps enterprises navigate this path without disruption or revenue loss. Reach out to us to discuss your project and get practical guidance.
Migration Strategies Under the Microscope: Specifics, Risks, Costs
Different system contexts require different strategies. The matrix below provides a structured basis for discussions with the responsible parties.
| Strategy | Works Best When | Geographic Rollout | Distributed Teams | Change Cadence | Risk Profile | Cost Drivers | Rollback Ease |
| Rehost | Infra constraints or time‑boxed compliance | Centralized, single region | Small core team | Low | Low–Medium | Cloud infra, migration tooling | High |
| Replatform | Need managed services, keep app logic | Regional waves | Multiple squads per component | Low–Medium | Medium | Platform licensing + integration re‑cert | Medium |
| Refactor / Strangler | Tight UX/feature goals; brittle integrations | Country‑by‑country with feature flags | Distributed component teams | High | Low–Medium (per wave) | Parallel run + shims | High |
| Replace (COTS) | Capability parity exists; time‑to‑value > purity | Phased domain rollout | Vendor + internal team mix | Medium | Medium–High | Customization + data migration | Medium |
| Coexistence | Revenue exposure is high; need canarying | Phased by site/BU | Split teams legacy/new | High | Low per change; Medium total | Dual run costs | High |
| Big‑Bang | Narrow scope; excellent parity tests; low revenue risk | Single event | Cohesive, co‑located | Low | High | Long freeze, all‑hands cutover | Low |
What to consider:
-

Geography
Multi-country ecommerce programs benefit from coexistence or strangler approaches to respect local tax, content, and regulation. Running legacy and new stacks side-by-side makes it possible to tailor compliance for each market without delaying the overall rollout.
-

Distributed teams
Large ecommerce groups often have engineering squads spread across continents. A practical model is to split responsibilities: legacy teams sustain current operations while new build squads deliver modernization.
-

High change cadence
Enterprises that update promotions, catalogs, and database records daily can’t afford an all-at-once launch. Without that safety net, even a minor misfire could snowball into lost sales across multiple regions.
After selecting the strategy, the focus shifts to preparing for migration.
What Every Enterprise Should Secure Before Starting Migration
Before you start pulling pieces out of a legacy platform, lock down the rules of engagement. Migration at enterprise scale should safeguard revenue, ensure compliance, and protect customer trust while the ground shifts beneath your teams.
The first anchor is scope and parity. Define customer‑visible parity that must not regress. Add non-functional parity, e.g., latency, throughput, security. This becomes your insurance when debates arise over what “done” means.
Next is the integration inventory: payments, ERP, CMS, search, analytics, etc. Each has owners, SLAs, and cutover rules. Miss one, and rollout stalls on hidden dependencies, not code.

Data deserves its own lane. Identify authoritative sources, map transformations, define backfill strategies, reconciliation reports, and retention policies. Without this, you risk drifting records, duplicated accounts, and audit findings that surface long after the migration team has moved on.
Performance targets need to be explicit. For each critical path, like login, product detail, cart, checkout, set p95 and p99 budgets. Don’t trust lab tests. Run soak tests with production-like data until you know how the system behaves under stress.
Governance matters too. Freeze windows, approval processes, feature-flag strategies, kill-switches. Without these, you end up firefighting instead of controlling exposure.
And finally, line up the people. Dual-run staffing to cover legacy and new, L1–L3 support ready on day one, training to prevent operator error, and clear communication plans for markets. A migration without people prep is just a technical demo waiting to collapse under real-world load.
Get these safeguards in place before the first line of code moves, and you’re setting up a migration program that can withstand the reality of enterprise ecommerce.
Our whitepaper “Smart Ways to Lower Ecommerce Infrastructure Costs” highlights where to look for savings and how to optimize spend without sacrificing quality.
Download the whitepaperArchitectural Blueprints for Modernizing Legacy Systems
With planning complete, execution starts. Architectural patterns here are practical tools to manage live traffic, distributed teams, and customer expectations.
-
The strangler fig
Instead of ripping out an entire platform at once, route specific capabilities into the new stack slice by slice. Checkout, search, and loyalty can move independently, reducing blast radius and giving teams room to breathe.
-

Anti-corruption layers
Legacy systems carry baggage: data models, naming conventions, half-baked business rules. An ACL stands between old and new, translating semantics and stopping leaks.
-

Compatibility shims
During coexistence, customers don’t care if they’re hitting legacy or modern code. They just expect accounts and sessions to persist. Shims maintain API and session parity, keeping shared logins and SSO intact while the back end shifts beneath them.
-

Blue/green and canary deployments
Parallel environments with staged exposure let you shift traffic gradually. If you do it right, rollback is instant. If you flip routing, users are back on stable ground. Skip this, and you leave the business with no safety net, as once you cut over, there’s no way back.
-

Shadow traffic
Nothing tests like production. By replaying real requests to the new services without exposing them to users, you validate behavior at scale and uncover edge cases long before they hit customers.
-

Saga patterns & idempotency
Distributed transactions are messy. Sagas coordinate multi-service workflows while idempotency guarantees retries don’t create duplicates. Without this discipline, one glitch in order processing cascades into customer service chaos.
-

Bulkheads & circuit breakers
In mixed-mode operations, failures spread fast. Bulkheads isolate services, while circuit breakers cut off failing dependencies before they drag everything else down. These patterns turn partial failure into graceful degradation instead of a full-scale outage.
One more pattern worth paying attention to is CDC & outbox. It focuses on replacing heavy batch ETL jobs with event-driven replication, capturing every change as it happens and ensuring idempotent delivery to target systems.
When using this principle for a financial services migration, we swapped a nightly ETL pushing 60M+ records into MongoDB for AWS DMS streaming changes into Kafka, with custom consumers updating MongoDB in near real time. As a result, the client got fresher data, lighter infrastructure costs, and a system that keeps up with the business instead of lagging a day behind.
These architectural blueprints are what keep complexity in check. Next, the spotlight moves to preparing and safeguarding the information that fuels the entire migration.
Preparing Your Data for Migration
A detailed data migration checklist, described in a separate article, outlines every critical step for successful data migration, so use it as your reference point. Below is just a short summary of what to keep in mind.
The first step, discovery, is about understanding your data in full. This is when you uncover mismatched sources, undefined ownership, and silent business rules that can break new systems. Skipping it means transferring legacy issues instead of fixing them. Clarity here sets the foundation for a clean migration.
Next comes mapping and transformation. This stage can’t be left to engineers alone and requires business owners to be involved, as data logic follows business realities, not just schemas. Together, they define validation rules for uniqueness and consistency across orders, customers, and addresses.
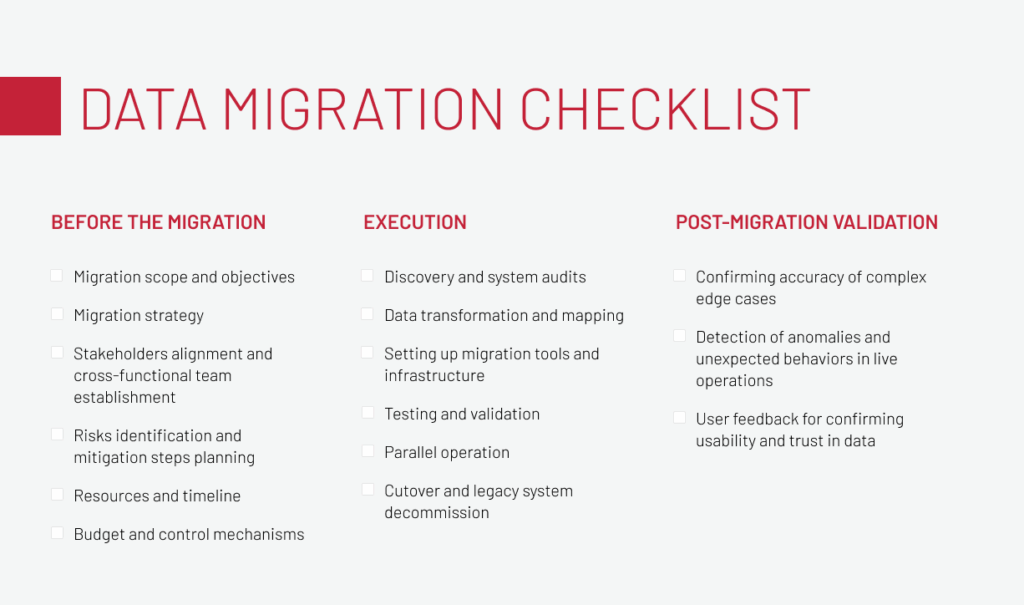
Cleansing must also be planned from the start: deduplicate, normalize, and decide how to handle outliers. Neglecting this step leads to reconciliation issues later, when mismatched records start affecting financial and operational accuracy.
Change data capture (CDC) and backfill should be planned together: full loads start the system, CDC keeps it current. Reconciliation reports validating aggregates and samples between old and new systems build trust along the way.
Finally, wrap the entire workflow in a structured governance model. This discipline leads directly to data integrity, where consistency, accuracy, and traceability are continuously verified at scale.
Solid data preparation lays the groundwork, but even the best foundation can fail if execution goes wrong. The next step is understanding where migrations typically break down and how to avoid those pitfalls.
Migration Mistakes & Anti-Patterns
Migrating legacy systems can fail for similar reasons. These are the recurring anti-patterns worth addressing early:
-
Big-bang cutovers without rollback
Launching everything at once without shadow traffic or staged exposure leaves no way to reverse course when errors surface. Even small defects can cascade into major outages.
-
Underestimating data work
Weak mapping, missing backfills, and poor reconciliation create financial drift, duplicate records, and compliance issues. Data gaps discovered post-cutover are costly to fix.
-
No idempotency in messaging
Without idempotent processing, retries generate duplicate orders and inconsistent states, which in turn overwhelm customer service and damage trust.
-
Performance tested only in labs
Benchmarks on limited datasets don’t reflect production. Without soak tests on real-world volumes, peak traffic exposes bottlenecks at the worst possible time.
-

Governance gaps
Unclear go/no-go criteria, missing kill-switches, and absent SLOs leave executives making critical decisions without reliable signals.
-

Ignoring SEO and content flows
Broken redirects, bad canonical tags, and orphaned pages reduce search visibility and organic traffic, directly impacting revenue.
-

People’s blind spots
Thin training, missing Level 1 runbooks, and unprepared on-call teams delay recovery and increase downtime when incidents occur.
These failure points are quite predictable. Addressing them upfront reduces risk and protects both revenue and operational stability. Now it’s time to shift focus and look at what truly separates smooth migrations from those that stall mid-way.
Best Practices for Successful Migration
The most effective migrations share a pattern: they reduce risk by layering safeguards across business, content, and operations. These practices are proven under the pressure of enterprise-scale ecommerce rollouts.
Run legacy and new in parallel where revenue is at stake
Keep legacy and modern platforms running side by side until the new stack proves stable. Parent–child site logic or routing rules let the new storefront inherit configurations, while shared identity ensures customers log in without friction.
-

If you skip it:
New front-ends launch with inconsistent prices, promos, or content, forcing hotfixes and freezes. Login issues spike cart abandonment, and a single checkout or tax bug can tank conversions with no rollback path.
Isolate CMS changes with explicit restrictions
Tag CMS components by target site or front-end to prevent cross-contamination. Otherwise, shared catalogs or templates can unintentionally overwrite content across old and new systems.
-
If you skip it:
legacy-only blocks may render in the new UI (and vice versa), causing CLS spikes, 404 errors, and dropped SEO rankings that force emergency content freezes and reactive debugging.

Design for financial and operational continuity
If downstream systems, such as ERP or WMS, accept only a single daily export, merge legacy and new feeds server-side until the new system fully takes over as the source of truth.
-
If you skip it:
exports from legacy and new systems overlap or conflict, creating duplicate or missing orders. Over time, this leads to failed closes, compliance flags, and serious trust issues in financial reporting.
Re-certify content and search integrations
Blogs and search indexing jobs must be updated to associate content with both legacy and new sites while they coexist. Skipping this means new content appears in one system but not the other, fragmenting analytics and damaging organic visibility.
-
If you skip it:
fresh posts, pages, or search results show up only in one environment, breaking navigation paths and analytics continuity. Traffic drops as search indices miss updated content, canonical links desynchronize, and SEO performance collapses across the ecosystem.
Leverage templates once you secure the first win
Codify infrastructure, CI/CD, CMS restrictions, and data flows into a reusable template, then localize it per market.
-
If you skip it:
each market rebuilds migration tooling from scratch, introducing unique bugs and compliance gaps. Rollouts slow down, on-call workload spikes, and teams waste effort maintaining inconsistent pipelines instead of improving the core migration framework.
How to put these best practices to work
The practices above are not just words, but the approaches we use in client work. Here is one example: moving a leading French cosmetics retailer from JSP to Composable Storefront. Our team approached the rollout as a sequence of safeguards rather than a single leap.
We launched new Spartacus child sites alongside the legacy parent sites so they could inherit existing settings and models. Where configurations were missing, we kept the parent as a fallback. We also maintained shared identity across both systems, ensuring customers could log in and keep their accounts intact throughout the transition.
On the content side, we introduced site-scoped CMS restrictions so only Spartacus-compatible components were served. Multi-site controls kept shared catalogs in order, which prevented layout errors and SEO regressions that typically surface when content crosses environments unchecked.
Finance and operations also required discipline. We merged daily order exports from both systems into a single file to meet ERP limits and avoid duplicate or missing entries. At the same time, we extended WordPress cron jobs to associate blog content with both platforms, keeping search visibility and analytics consistent.
Once the first business unit stabilized, we codified everything into a reusable migration template. This included infrastructure patterns, CI/CD, CMS restrictions, and data flows, with localized adjustments for market-specific requirements. That template turned later migrations into repeatable programs, which became faster to deliver, easier to manage, and less risky to operate.
Cutover & Rollback: Practicals
Cutover is where risk concentrates because it’s the moment traffic, data, and revenue move from the legacy system to the new one. Any gap in readiness can turn into downtime, lost orders, or broken customer journeys. To keep control, teams should lock in these practices:
- Expose the new system gradually with a canary release by country or business unit, then ramp traffic in controlled stages.
- Maintain rollback readiness through DNS or routing switches at all times.
- Define a runbook covering roles, communication channels, pager rotations, freeze windows, verification steps, rollback triggers, and time-boxed checkpoints.
- Mirror production traffic into the new stack before customer exposure and compare logs and metrics with the legacy system.
- Reconcile orders, inventory, and customer data at defined intervals, with sign-off required after each checkpoint.
Once traffic shifts and rollback plans are tested, we move to measuring how the new system performs in the real world.
Our whitepaper “Speed Through the Mess: How to Build Scalable Retrieval in Complex Stacks” breaks down proven strategies for building resilient retrieval at scale.
Download the whitepaperPost-Migration Metrics & Health Checks
Post-migration is the validation phase. At this point, the new system must prove itself across three dimensions: reliability, data quality, and business outcomes.
Reliability & performance (SLO-grade)
The first lens is reliability. We track availability against defined SLOs and watch error-budget burn closely. Latency is measured at the p95 and p99 levels across the most critical paths, including login, search, product detail pages, cart, and checkout.
Throughput and saturation metrics round out the picture: requests per second, queue lag, and connection or thread pool utilization. Using SLOs and an error-budget policy, as formalized in Google’s SRE framework, lets teams balance stability with the need to keep delivering change.
Data quality
The second lens is data. We track freshness lag and CDC replication delay to prevent domains from drifting out of sync. Reconciliation between legacy and new systems helps catch mismatches in orders or inventory, while monitoring duplicates, late events, and dead-letter queues reveals recurring issues early.
In a migration for a large cosmetics retailer, we swapped out a messaging backbone that had been losing retries. By moving to a system with stronger retry semantics and deeper logging, message loss dropped by about 15% within weeks of go-live. It proved once again that in mixed-mode operations, you can’t compromise on data freshness or idempotency.
Business outcomes
The third lens is business performance. We track signals across three areas:
-

Core ecommerce metrics:
conversion rates, cart abandonment, average order value, order success rate.
-

Delivery metrics:
release frequency, change lead time, mean time to recovery.
-

Cost metrics:
infrastructure, licenses, and support run costs compared against the baseline.
Faster sites almost always perform better commercially, and multiple industry studies confirm a direct correlation between page speed and conversion. For instance, Deloitte’s report says that a 0.1-second improvement in mobile load time boosted retail conversions by 8.4% and travel conversions by 10.1%. It proves that even small speed gains can translate into measurable revenue growth.
We’ve walked through the migration process with its specifics, pitfalls, and technical details. But there’s also the operational side that shapes the strategy just as much as the tech itself. For example, costs.
Economics of Migration
Migration economics is as much a strategy question as it is a technology one. Leadership needs to see the full financial picture. And it’s not only what it costs to get to the new platform, but also what it costs to run it, stabilize it, and extract value over time. Looking at a three- to five-year horizon gives a realistic view of both TCO and ROI.
TCO and ROI components (3–5 year view)
The investment side spans multiple layers that need to be visible to leadership:
-
Build & transition:
engineering, data remediation, test automation, non-production environments, overlapping licenses during coexistence, UX rebuilds.
-
Parallel-run & coexistence:
dual infrastructure, shadow traffic, compatibility shims, and operations playbooks supporting both worlds.
-
Change management:
training, communication, process updates, and L1/L2 readiness for new workflows.
-
Stabilization:
post-cutover bug backlog, performance tuning, and observability hardening to keep systems steady.
-
Ops run cost:
managed services, support contracts, security tooling, and the ongoing on-call burden.
-

Risk premiums:
rollback contingencies, extended cutover windows, and vendor penalties that must be budgeted upfront.
Hidden costs (commonly missed)
Even well-planned migrations underestimate these areas, mainly because they appear routine until execution exposes their complexity:
-
Data work
Mapping, cleansing, and re-indexing usually take longer than expected. Legacy systems accumulate inconsistencies, custom fields, and mismatched IDs that aren’t visible until migration begins, stretching timelines far beyond core application updates.
-
SEO migrations
Redirect maps, canonical tags, and freeze windows may seem like formalities, yet even small mistakes can trigger major ranking drops and long recovery periods. Overlooking this work can easily turn into a months-long loss of organic visibility.
-
Identity & SSO
Reworking identity, SSO, and consent management often hides major costs that come from broken sessions or misconfigured logins disrupting user access, increasing support load, and potentially leading to revenue loss.
-
Integration re-certification.
Payment, tax, ERP, and WMS integrations often need renewed certification after platform changes. Teams assume existing connections will hold, but small schema or endpoint updates can invalidate prior approvals and stall production.
ROI levers
The payoff of modernization comes through:
-

Faster delivery:
reduced change lead time and lower MTTR improve feature velocity and resilience.
-

Improved conversion:
UX and latency gains directly lift sales performance.
-

Lower run costs:
managed platforms and right-sized infrastructure cut operational spend.
-

Reduced risk:
fewer Sev-1 incidents, stronger audit posture, and better compliance reduce disruption costs.
While understanding migration economics helps leaders plan investments and measure ROI, security and compliance require a different lens entirely. These controls must be designed into the migration plan from day one to protect data, maintain trust, and meet regulatory obligations as systems evolve.
How to Ensure Security & Compliance During Migration
Security and compliance have to move in lockstep with migration. The risks grow as data shifts and systems run in parallel, so clear safeguards are essential.
-

Tip 1. Limit access
Use least privilege and just-in-time access for all migration tooling. This minimizes exposure and reduces the impact if credentials are misused.
-
Tip 2. Rotate secrets
Centralize secrets management and align key rotation with cutover windows. That way, old credentials don’t linger in production after the switch.
-
Tip 3. Secure data flows
Protect every data stream with TLS, mask sensitive information in lower environments, and apply field-level encryption when regulations require it.
-
Tip 4. Track everything
Maintain audit trails for schema changes, data moves, and elevated actions so both governance teams and auditors have a reliable record.
-
Tip 5. Harden the supply chain
Run SAST/DAST scans, generate SBOMs, and enforce release attestation to catch risks before they enter production.
-
Tip 6. Test recovery
Validate backups and point-in-time recovery before and after cutover, ensuring the system can withstand disruption under real operating conditions.
To ensure these tips are fully implemented and maintained, people across all departments should be aligned. This is one more strategic factor to keep in mind for successful migration.
Aligning People and Processes for Smooth Migration
A successful migration relies on structured governance that connects every stage, from planning to stabilization, into one coordinated process. It begins with a communication plan that keeps all teams aligned.
Governance must also define who does what. IT teams manage tooling, infrastructure, and testing, including ETL and CDC setup, and snapshot creation. Business domain experts validate semantics and mappings to ensure data accuracy, while compliance officers handle regulatory checks under GDPR, HIPAA, or other relevant standards.
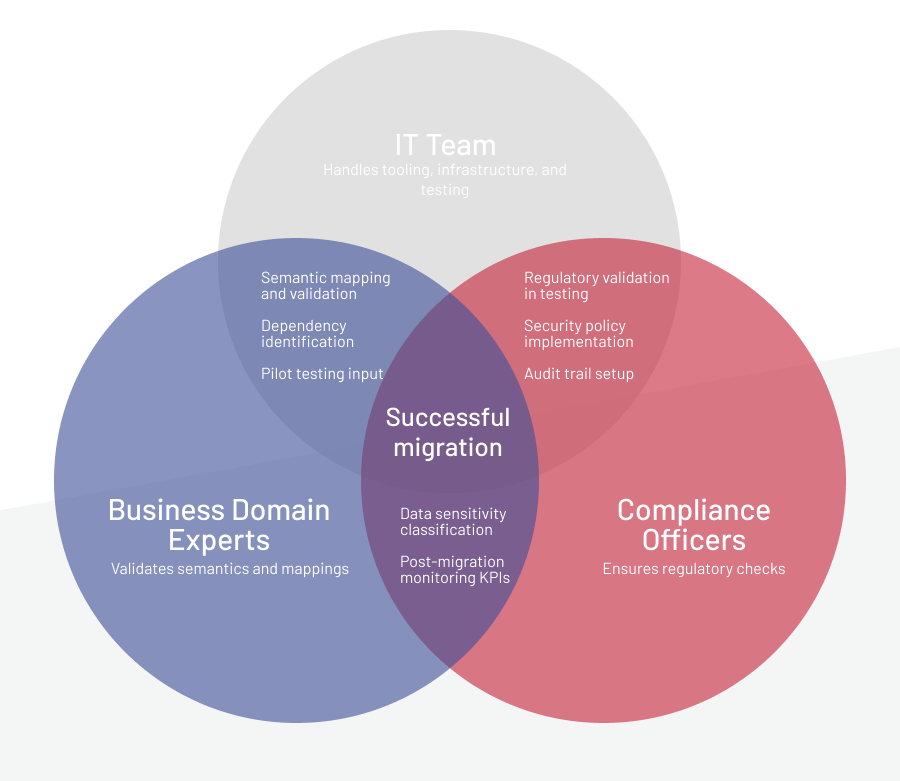
Finally, focus on people as much as processes. Transparent communication, early training, and dedicated support after cutover help teams adapt quickly and maintain productivity as the new systems take hold.
What Successful Migrations Look Like in Practice
Case studies are where the legacy system migration strategy meets execution. They show how patterns like coexistence, replatforming, and modernization play out in real enterprises facing high stakes.
Migrating microservices to Amazon EKS
A credit rating agency needed to move from self-managed Kubernetes to Amazon EKS while upgrading Java/Spring Boot across dozens of services under a deadline. Managing dependencies across microservices added complexity as each had its own release cadence, configuration, and inter-service contracts to maintain. We ran old and new gateways side by side in a test with instant redirection to the stable path for rollback.
Teams also resolved routing conflicts, modernized CI/CD pipelines, validated endpoints, and introduced Datadog, SonarQube, and Veracode for telemetry and security.
Full replatforming from .NET to SAP Commerce Cloud
A medical retail leader outgrew its legacy .NET stack, which slowed development and limited scale. Our team replatformed to SAP Commerce Cloud with a modern Spartacus front-end to bring flexibility and speed.
We migrated data through Cloud Hot Folders using structured CSV imports and built deep, two-way integrations with SAP S/4HANA and NestPay. We also delivered back-office widgets and action buttons that streamlined complex quote flows. The new platform now scales for new product lines and supports faster and more reliable releases.
To Sum Up
Enterprise migration is a structured program that blends strategy, engineering, and governance. Success depends on a few critical components: making decisions based on business priorities rather than technical convenience, and aligning the pace of modernization with organizational readiness. It also means treating data as a core business asset, not a byproduct of migration, and keeping a close eye on metrics.
Once these insights are in place, organizations can refine their roadmap, validate priorities, and decide where to focus next. For teams planning or evaluating a migration, our migration services help benchmark key metrics and build a strategy tailored to your business context. We’re ready to help!
FAQ
-
How do I choose between migrating, modernizing, and stabilizing?
To choose between migrating, modernizing, or stabilizing, assess business criticality, change pace, integration complexity, compliance, and talent. High change favors modernization, urgent compliance favors migration, and low-risk, stable systems justify temporary stabilization with continued monitoring and security.
-
What should be locked before any production change?
Before any production change, define scope and customer parity, confirm integrations, set latency targets, and prepare runbooks with rollback steps. Establish data ownership and reconciliation to keep systems aligned and prevent drift after traffic switches.
-
How do I keep data consistent during coexistence?
Keep data consistent by combining full initial loads with CDC. Use idempotent consumers to avoid duplicates, reconciliation reports to detect mismatches, mirrored traffic for validation, and repair paths to handle late or failed events during coexistence.
-
Which metrics prove migration success?
Migration success is measured across reliability (SLOs, latency, error budgets), data health (replication lag, reconciliation accuracy), and business impact (conversion, order success, lead time, MTTR, cost trends), proving the new system delivers stable, measurable value.
-
Where do most migrations fail?
Most migrations fail at integration points, such as missed redirects, broken sessions, or misaligned exports. Clear ownership, proven templates, and staged exposure with rollback options keep these weak spots from turning into full-scale outages.
Backed by years of experience advising enterprise clients, Andreas Kozachenko, Head of Technology Strategy and Solutions at Expert Soft, offers a perspective on planning legacy system migrations that align with long-term business and technical goals.
New articles

See more

See more

See more

See more

See more
