How to Use Caching to Improve Microservices Performance

Caching in microservices is completely different from that in a monolith, both in goal and implementation. It’s more than just a way to improve speed, it’s about a way to keep the system stable as it scales. When one user action triggers dozens of remote calls, even small delays add up fast. Caching techniques in microservices help absorb that pressure, reducing strain on services and keeping response times consistent, even under heavy load.
If you’re designing for growth or aiming to keep your microservices responsive and reliable, the following caching strategies in microservices from Expert Soft’s hands-on experience offer practical ways to make caching work where it matters most. Explore!
Quick Tips for Busy People
Here is a brief summary of critical caching mechanisms in microservices that every team working with microservices should keep in mind:
- Cache where it counts: remote access adds latency, risk, and load, so cache where the impact is highest.
- Use the right caching pattern: match entity, query, or aggregation caching to the data and usage pattern.
- Choose cache placement deliberately: select cache type based on speed, scope, and system role, don’t default.
- Treat invalidation as core logic: TTLs aren’t enough, use events or versions for real-time accuracy.
- Track evictions and churn: frequent evictions signal memory pressure or misconfigured TTLs.
- Make your cache observable: monitor hits, misses, stale reads, and invalidation flows across layers.
Keep reading for practical steps on how to do caching in microservices the right way.
Data Service Overheads: Why Microservices Don’t Scale for Free
Modularity is one of the biggest selling points of microservices. But what doesn’t get enough attention until your system hits real load is the hidden cost of remote data access.
In a monolith, grabbing a piece of data might be as simple as a method call: fast, local, and practically free. In microservices, each service owns its data and is isolated by design. So, within cross-service calls, the data that was once available in memory must now be fetched over the network. This often adds overhead, such as serialization, authentication, and sometimes retries or rate limiting. At scale, these costs accumulate, turning clean architecture into a performance constraint.
Worse, not all service dependencies are obvious. For example, if ten services rely on a central user service for identity resolution, its performance bottlenecks ripple throughout the system. That’s the fan-out effect: one overloaded service can quietly drag down seemingly unrelated parts of the system.
Local Access Costs vs. Remote Access Costs
The critical part of all these cross-service calls and data access costs depends on latency. Let’s put some numbers on it:
| Access Type | Average Latency |
| In-process memory | ~10–100 nanoseconds |
| Embedded in-memory cache | ~0.1–1 microsecond |
| Redis (local) | ~100–300 microseconds |
| Redis (remote/AZ) | ~1–5 milliseconds |
| Internal HTTP/gRPC | ~5–50 milliseconds |
| Cross-region cal | 50–300+ milliseconds |
The implication here is that as systems grow, the number of requests per user action increases, and when these requests form chains of several cross-service calls, latency stacks up quickly, and so do costs. And that’s before accounting for retries, contention, and serialization overhead. In high-load conditions, this quickly becomes unsustainable.
This is where caching plays an essential role. By storing frequently accessed data closer to where it’s needed, it collapses multiple expensive operations into cheap, in-memory lookups. However, in microservices, where the state is distributed and data flows asynchronously, this must be done deliberately and with architectural discipline.
Caching Types in Microservices
Different data calls for different caching strategies. Balancing between various caching types in a microservices architecture means the balance between smooth performance and cascading latency. Below is a list of caching types in microservices and when to use them.
Entity caching
Entity caching stores individual objects, such as a user or product, typically by their unique ID. It’s most effective for data that is frequently read but rarely changed, such as access control lists, user profiles, or feature flags. Instead of fetching the same data repeatedly, services can reuse cached entries, reducing latency and easing the load on the source system.

A common risk is caching mutable data without a proper invalidation strategy, which leads to inconsistencies. Additionally, you need to make sure that only the owning service can update or clear the cache and that entity copies reflect the correct version.
Query caching
Query caching saves the results of parameterized queries, like “all open orders for user X” or “products under $50.” It’s especially useful when the underlying queries are expensive or aggregate data from multiple sources.
This approach works well when parameters lead to a finite result space and query results change less frequently than they’re read. This makes query caching a go-to option for dashboards or filtered product listings.
What to pay attention to:
- Serialization of query parameters must be normalized to avoid cache fragmentation.
- Often, query results change make TTL tuning difficult, which is specifically tricky as for some pages, 5-minute-old data is fine, while in others, it’s unacceptable.
For this type of caching, invalidation is also a challenge. To make it efficient, we usually use query caching primarily at the API gateway or BFF layers, where results can be assembled and invalidated holistically. We also avoid query caching deep within service chains to maintain clear data ownership.
Aggregation caching
Aggregation caching stores full responses assembled from multiple services, such as product pages or dashboards that include pricing, stock, and metadata. Instead of calling every service on each request, the system can return a single cached result, which greatly improves performance.
What to pay attention to:
- Balancing invalidation for the cases when only a part of the aggregate changes. For this, structure your TTLs to match the most volatile component, or introduce sub-fragment caching where each piece can be refreshed independently.
- Establishing a clear ownership for invalidating the aggregated cache. Here, the following rule can help: if a single service is building and returning a full view to the client, it owns the cache.
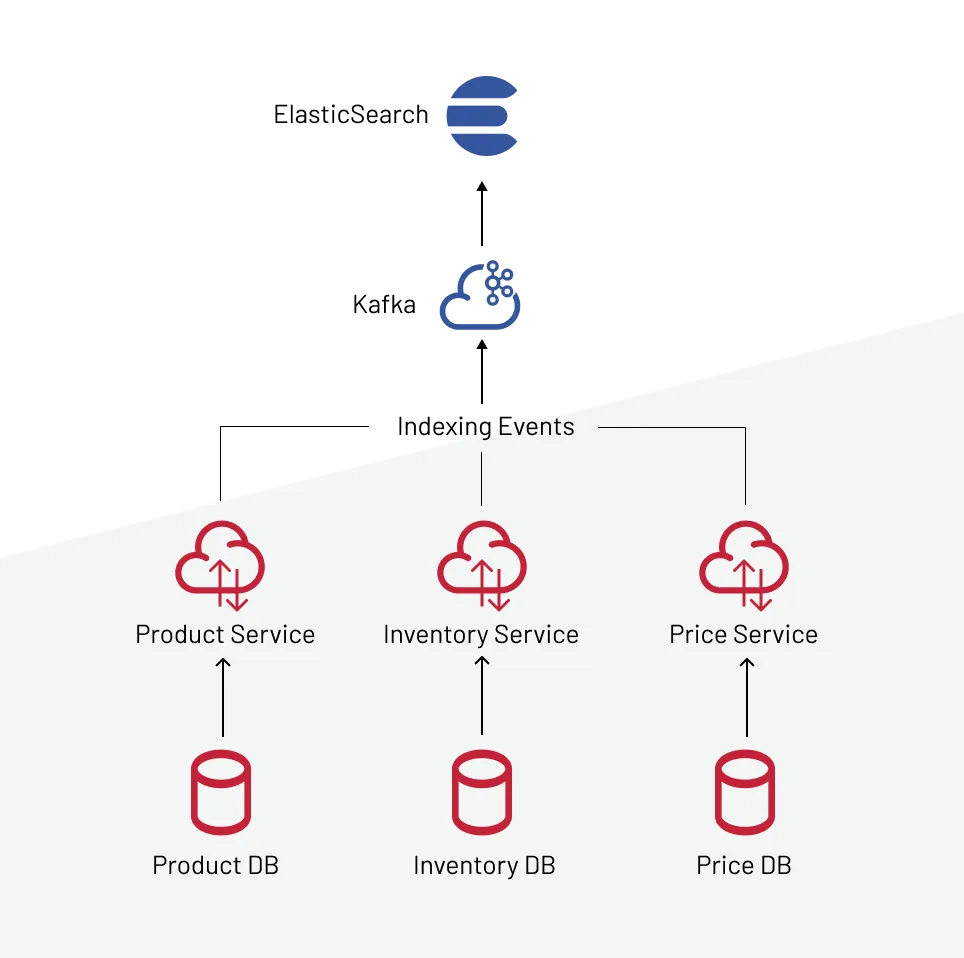
Elasticsearch as an aggregated cache layer
Elasticsearch is often used as a high-performance aggregation cache for search-heavy systems. Because of index-level denormalization of data and built-in pagination, scoring, and filtering, it provides fast querying and low-latency reads, being suitable for filtered product views, search results, and SEO-optimized content.
But Elasticsearch isn’t designed for transactional data. Caching volatile fields like inventory or price directly in the index is risky unless updates are backed by an event stream that handles frequent reindexing. Reindexing must also be done carefully to avoid performance hits or downtime.
But knowing what to cache is one thing. Just as important is where you put that cache in your system.
Caching Placement Strategies in Microservices
From client-side layers to distributed clusters, each cache placement serves a different purpose. Knowing how to implement caching in microservices begins with choosing the right layer and configuration for your needs.
| Caching Type | Where It’s Used | Best For | Limitations |
| Client-side | CDN, browser, Edge | Static content delivery, preloading pages or assets | No control over invalidation, cannot be trusted for sensitive or volatile data |
| Embedded | Libraries: Caffeine (Java), Guava, Node’s lru-cache, etc. | Per-request high-frequency lookups, system-level flags, dictionaries, access permissions | No sync across instances, memory-bound, no built-in fault-tolerance |
| Client-server | Redis, Memcached | Centralized cache for multiple app instances, session stores, shared TTL-based datasets | Must be partitioning, single point of failure unless clustered |
| Distributed | Hazelcast, Ignite, ElastiCache Cluster Mode | Horizontally scalable caching, cache that holds a large working set, fault-tolerant and replicated environments | Split-brain risks, eviction issues, need for deep integration with platform runtime |
| Sidecar | Small proxy/cache alongside the service container | Offloading high-volume reads (like token validation), sharing cached data across instances, and externalizing cache logic from business code | External configuration management, observability gaps, not suited for user-specific or high-cardinality data |
After choosing the right cache and placement, comes another challenge, keeping it accurate.
Invalidation Strategies
With cache invalidation, the golden rule is: caching stale data is worse than not caching at all. And keeping in mind that invalidation is the hardest caching challenge, this rule should be your north star, along with some practices below.
TTL invalidation
Time-to-live (TTL) is the most common and easiest way to manage cache freshness. TTLs work for non-critical data and predictable update cycles.
However, in microservices with several caching systems and changes happening at any time, TTLs often struggle to adapt. A key might expire too late, or too early, leading to stale reads or unnecessary recomputes. Conflicting TTLs between systems (e.g., Redis vs. CDN) can create inconsistency. If many keys expire simultaneously, you risk a cache stampede that overloads back-end services.
That’s why the best advice here is to use TTLs with caution. They’re lightweight and easy to implement, but not reliable for sensitive or frequently changing data.
Event-driven invalidation
This is the most accurate and responsive strategy, tying cache invalidation directly to data changes. When the source of truth updates, it emits an event: a database trigger pushes to an event bus, a CMS sends a webhook, or business logic posts a message to Kafka, SNS, or Redis Pub/Sub. Subscribers then invalidate or refresh their cache entries in real time.
The benefits are clear: caches reflect actual changes as they happen, not assumptions. But this comes with architectural demands:
- Clear ownership: only the system that owns the data should emit invalidation events.
- Consumer discipline: any service or cache relying on that data must subscribe and react reliably.
- Delivery guarantees: messages must reach all subscribers, as missed invalidation means serving outdated data.
When implemented well, event-driven invalidation delivers precision and system coherence, but it requires more coordination and testing than passive strategies like TTL.
Versioned data and cache coherence
Versioned caching offers an alternative approach to traditional invalidation by embedding a version identifier, such as a timestamp or hash, into the cache key. When data changes, it’s written with a new versioned key, allowing older entries to expire naturally over time.
While this doesn’t eliminate the need for invalidation, it shifts the strategy: instead of explicitly deleting stale data, you let version mismatches guide cache behavior. This reduces coordination between services and avoids invalidation races.
Versioning is especially useful for semi-static content like product catalogs or CMS-managed blocks, where real-time accuracy isn’t always essential. It simplifies cache logic and adds resilience so long as the system can tolerate the brief coexistence of old and new data.
What Happens When Cache Gets Full
When a cache exceeds its capacity, whether due to memory limits in embedded caches or key count limits in systems like Redis or Memcached, it starts evicting entries. In microservices, cache churn lowers your hit rate, and losing critical keys like auth tokens can trigger cascading failures. Without visibility, these evictions often go unnoticed until users feel the impact.
Common eviction policies include:
-
- LRU (Least Recently Used): the default in most caching systems. It evicts entries that haven’t been accessed recently. It works well in general, but hot keys can be discarded under bursty access patterns.

-
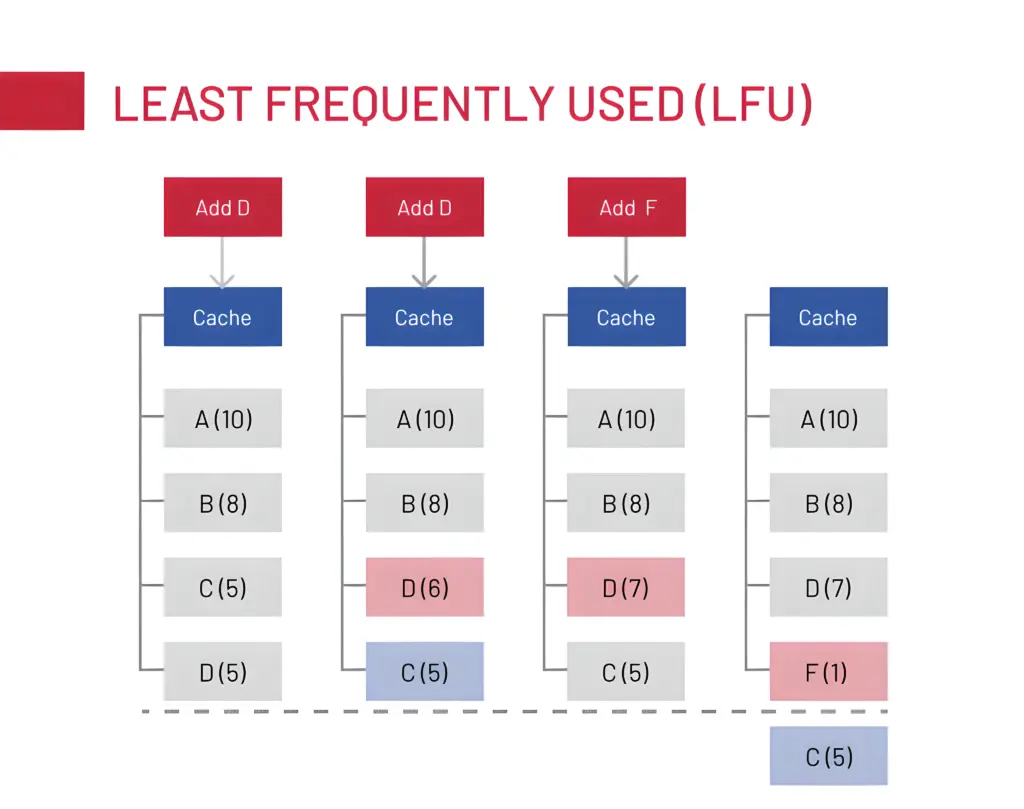
- LFU (Least Frequently Used): prioritizes keys accessed most often over time. More stable for long-lived hot data, especially in services with consistent traffic patterns.
-
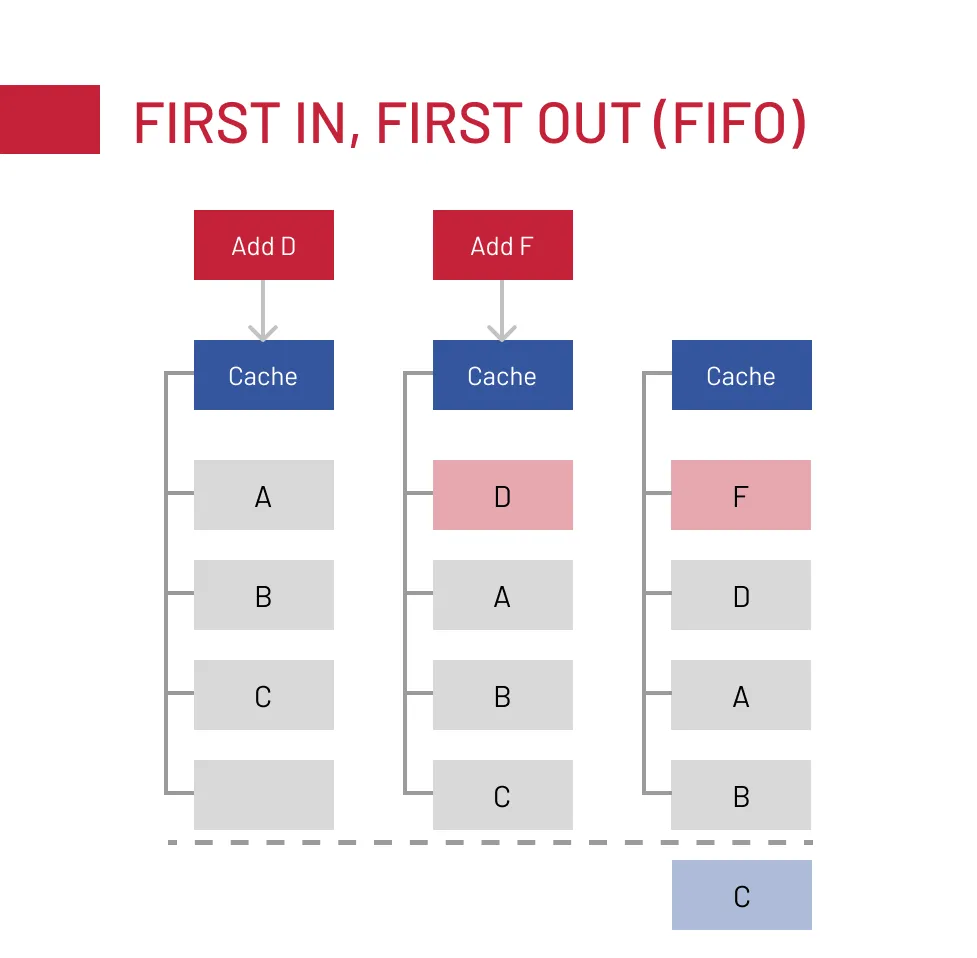
- FIFO (First In, First Out): evicts the oldest entries regardless of access. Simple and predictable, but ineffective when some data is accessed far more than others.
The solution is to segment your cache intentionally. Don’t let high-value data like user sessions or pricing compete with low-priority metadata for the same memory space. By separating hot paths from cold ones, either through dedicated namespaces, key prefixes, or memory allocation, you reduce the risk of critical data being evicted under load.
A monitoring tip for you: track eviction causes and per-key eviction frequency. A key evicted too often is a candidate for dedicated placement or memory allocation.
And while we mentioned observability, let’s take a deeper look at it.
Observability in Microservice Caching
Caching failures in microservices are often silent. The service usually doesn’t crash, it just becomes slower, inconsistent, or overloaded. That’s why observability is critical. Here is what to monitor.
| Metric | Why It Matters | Example Alerts |
| Cache hit/miss ratio | Core health indicator of cache effectiveness. A drop may indicate configuration issues or cache pollution. | Hit ratio drops >30% in a 10-minute window |
| Eviction rate | Signals memory pressure, inefficient TTLs, or lack of segmentation. High eviction often correlates with performance issues. | Eviction count >500/min in user-session cache |
| Load time on miss | Reflects the back-end cost of a cache miss. Helps prioritize what’s worth caching. | Back-end latency on miss >1s sustained over 5 minutes |
| Invalidation events | Tracks how well the cache stays in sync with the system of record. Low or missing events suggest stale data risks. | Invalidation event volume drops below threshold for key group |
| Stale reads detected | Helps identify silent data inconsistencies, especially in eventually consistent systems. | Stale read rate >5% in product-detail cache |
To make caching observable and ultimately reliable, you need to log and monitor more than just outcomes. Start with structured logging that includes a cache_status field (hit, miss, or stale) for each relevant request. This makes it easier to trace cache behavior in context.
Group your logs and metrics by key categories or use cases (e.g., user-profile-cache, search-results-cache) to pinpoint where issues are concentrated. It’s also helpful to log the TTL age at the time of access. This exposes ineffective TTL settings, like values that expire too soon to be useful or linger far beyond relevance.
For tooling, Prometheus and Grafana are reliable go-tos for tracking cache metrics. Jaeger or OpenTelemetry can expose cache spans in distributed traces. And most caching layers, like Redis or Memcached, offer built-in stats for memory usage and eviction behavior. If you want caching to stay an asset instead of a liability, you need to make it visible.
To Sum Up
Caching in microservices architecture is a structural necessity. But to work at scale, it requires more than plugging in Redis. You need the right strategy for each data type, clear ownership, well-placed cache layers, and reliable invalidation.
Entity and other types of caching in microservices can solve different problems, but without observability and discipline, they can just as easily introduce new ones.
We’ve applied these practices in high-load, distributed systems and know where they succeed and where they fail. If you’re facing performance bottlenecks or cache complexity, feel free to reach out. Expert Soft’s team is always open to conversation.
FAQ
-

How to use Redis cache in microservices?
Use Redis as a centralized cache for entities, queries, or session data across services. Partition keys by context, apply TTLs thoughtfully, and implement invalidation through pub/sub events or versioned keys to maintain consistency and reduce cross-service load.
-

How does caching work in microservices?
Caching stores frequently accessed data closer to where it’s needed, reducing remote calls, latency, and system load. It works best when integrated into the architecture with clear ownership and invalidation logic.
Andreas Kozachenko, Head of Technology Strategy and Solutions at Expert Soft, specializes in optimizing microservices architectures. His extensive experience helps enterprises leverage caching to enhance performance, scalability, and reliability in complex systems.
New articles

See more

See more

See more

See more

See more
