Complete Data Migration Checklist to Ensure Zero Surprises During Migration

Large-scale data migrations are often a stressful process for ecommerce platforms as they push core systems, compliance, and customer operations to their limits. If something goes wrong, you’ll see it almost immediately in revenue loss, compliance penalties, and reputational damage.
That’s because large-scale migrations involve countless moving parts, and even experienced teams can overlook details that turn critical later. To bring some order to the chaos, I’ve put together a practical database migration checklist. Focused on the essentials, the checklist is still solid enough to serve as a steady reference alongside your plan.
Quick Tips for Busy People
Here are key takeaways from this article:
- Why the checklist matters. Checklists spotlight where migrations usually stumble: incomplete inventories, broken relationships, system drift, cloud slowdowns, or weak monitoring that undermines confidence.
- Laying the groundwork. Scope, metrics, and strategy are the basics everyone sets. The nuance is in catching hidden dependencies and compliance requirements before they trip you up later.
- Turning plans into action. Discovery, mapping, testing, and cutover are standard. The challenge comes when overlooked details appear — a reminder that even small slips here can snowball under production load.
- Stabilizing after go-live. Everyone expects some turbulence, but edge cases, anomalies, and user feedback often show things no test run ever reveals. Structured monitoring and open channels make the difference between quick stabilization and lingering doubt.
Now let’s walk through the full data migration validation checklist, covering planning, execution, and post-migration validation.
Why Enterprises Can’t Afford a Migration Without a Safety Net
Skipping a migration checklist is like moving fast without a safety net: you might get away with it, but the chances aren’t great. And when migrations do go wrong, the same problems tend to show up again and again:
-

Unplanned downtime
In 2025 research 46% of organizations said their toughest migration projects caused five or more hours of downtime, which is enough to disrupt customers and throw internal workflows off track.
-

Compliance breaches
If personal data is lost or exposed during migration, it may raise GDPR or HIPAA concerns and result in regulatory issues or reputational setbacks.
-

Escalating project costs
Research cited by Forbes shows that only 36% of data migration projects stay within their forecasted budgets, highlighting how common cost overruns and delays are in large-scale migration efforts.
-

Poor coordination inside the team
Technical and business perspectives may differ on how data is understood. For instance, one system might store a country as “UK” while another uses “GB,” and without alignment such differences can break reporting.
-

Lack of recovery options
Enterprises that overlook rollback planning often find out the hard way that one corrupted batch can stop operations for days, with no path to recovery.
These risks highlight why a structured approach is essential. The following checklist breaks down the critical steps enterprises need to plan, execute, and validate data migration.
Every migration has hidden traps. Expert Soft’s team has navigated them before and can help you avoid downtime, compliance risks, and runaway costs.
Get in touch with usComprehensive Data Migration Checklist
The checklist brings planning, execution, and post-migration checks into a single framework. This helps reduce the likelihood of common issues in enterprise projects, from incomplete inventories to performance drops after cutover.
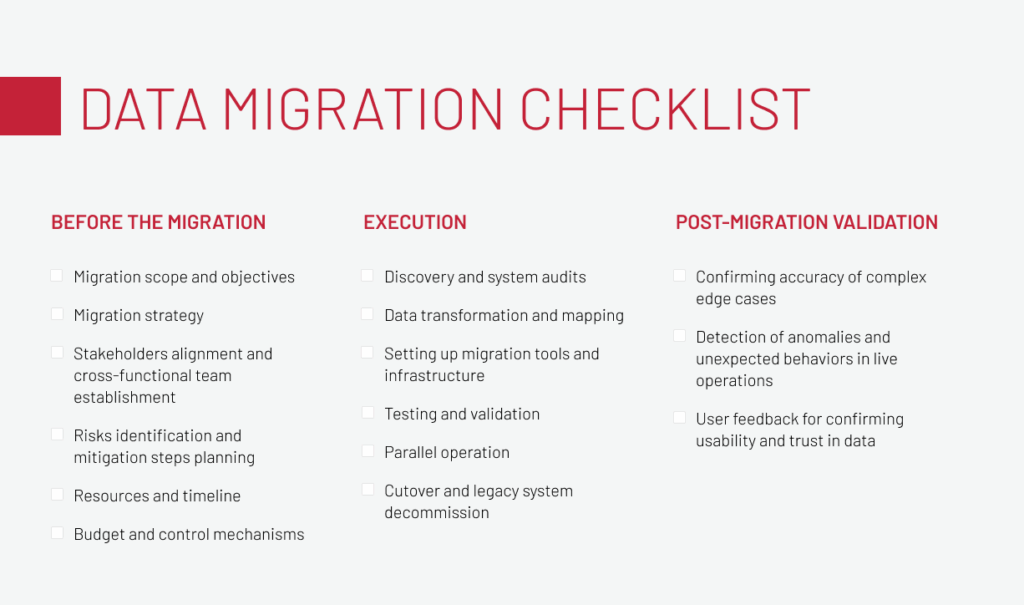
Before the migration: build a plan
Many failures in data migration can be traced back to gaps in preparation. This stage sets the boundaries, resources, and controls that determine whether execution will stay on track or collapse under pressure.
Define migration scope and objectives
A migration plan starts with scope. Cover the following points to set a clear foundation:
-

Clarify the purpose
Before diving into any migration, get clear on the “why.” Are you moving to the cloud for upgrading outdated infrastructure or merging systems after an acquisition? Defining the purpose first keeps the work grounded in business goals and prevents the project from drifting off course once things get technical.
-

Set measurable success criteria
Turn the big goal into trackable targets, like what system availability should look like during and after cutover, which compliance checkpoints have to be met, or what the KPIs are for response time. With those markers in place, everyone’s working from the same yardstick to track progress and agree when the job is done.
Select the migration strategy
I won’t be rehashing here the textbook distinctions of big-bang, phased, parallel, and hybrid migrations. What matters in practice is how you stress-test the choice against your own environment.
A few practical angles worth double-checking:
-

Rollback safety
If a batch fails halfway, big-bang offers little room to recover, while phased or hybrid approaches give you safer rollback options.
-

Downtime tolerance
A big-bang cutover may work if your business can handle several hours offline, but parallel or phased strategies are better when even minutes of disruption are costly.
-

System coexistence
Running old and new systems side by side points toward a parallel or hybrid model, where reconciliation between platforms is built into the plan.
-

Performance surprises
A big-bang switch leaves little margin if load tests miss something, whereas phased rollouts let you catch scaling issues earlier.
-

Compliance constraints
Strict regulations often push teams away from big-bang and toward staged rollouts, where audits and checkpoints are easier to manage.
In short, if you need minimal downtime and a safety net for rollbacks, a phased or hybrid strategy is usually the way to go. But if speed and simplicity are the priority and your business can handle short disruptions, a big-bang or parallel cutover might be the better fit.
Align stakeholders and form a cross-functional team
Migrations fail when ownership is vague, as different teams see the same data in different ways. IT focuses on pipelines, business teams think in rules, while compliance teams worry about regulations. When those perspectives don’t align early, problems build up quietly and only surface after the migration is finished. The best way to avoid that is to bring all parties together from the start, so everyone speaks the same language and follows the same checks.
Typical roles include:
-
1
DBAs and IT specialists
Handle ETL setup, infrastructure, and testing.
-
2
Business domain experts
Validate semantics and ensure business rules are preserved.
-
3
Compliance officers
Ensure encryption, audit trails, and regulatory checks are embedded.
-
4
IT governance roles
Enforce ownership, approvals, and reporting across the data transfer process.
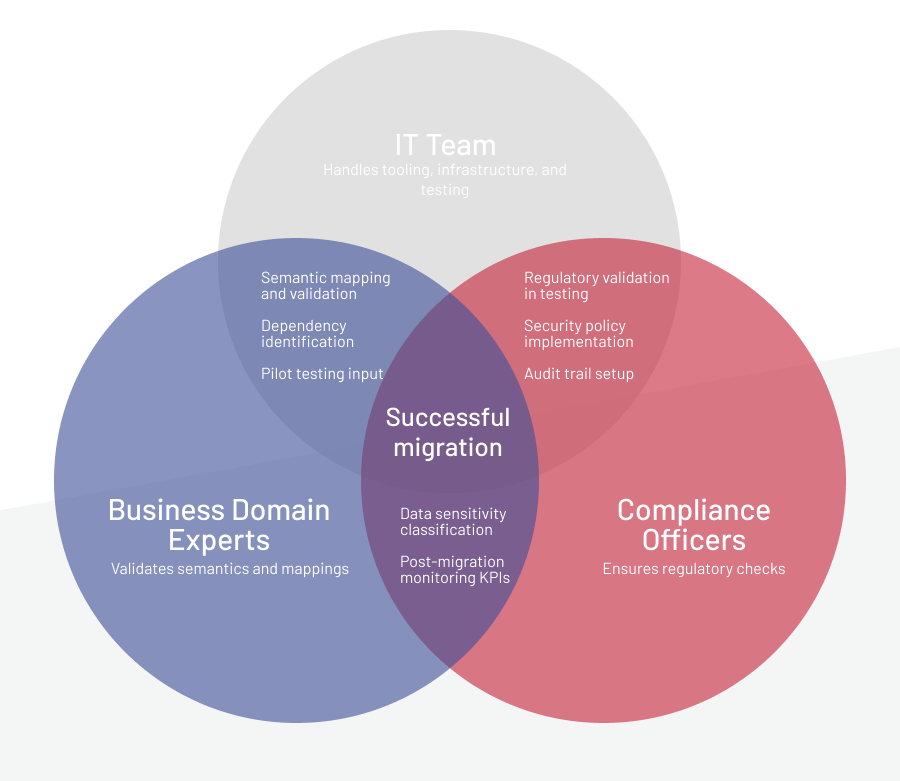
Clear ownership of semantics, validation, and rollback removes confusion and helps catch issues before go-live, instead of after.
Identify risks and plan mitigation steps
Every migration comes with familiar risks, like corrupted data, broken transformations, compliance gaps, and workflow disruptions. The difference lies in how well you prepare for them.
-
Set aside a budget
to cover hidden costs such as unexpected API charges or rework.
-

Define reconciliation rules
for data integrity when old and new systems run in parallel.
-
Integrate GDPR, HIPAA
or other regulatory checks into automated testing so gaps surface before cutover.
-

Build immutable snapshots
at each phase to avoid irreversible errors.
Allocate resources and set a realistic timeline
A migration plan can look perfect on paper but still fall apart once you start running it.
-
Use the right tools
Make sure ETL, monitoring, and auditing systems are in place before you begin.
-
Set up proper environments
Build sandbox and staging setups that mirror production as closely as possible.
-
Plan for drift
In one retail migration, the team lost four weeks dealing with parallel system drift that hadn’t been factored into the schedule.
-
Build in slack
Extra time you put in is insurance against risks that inevitably appear.
Establish budget and control mechanisms
Costs climb fast when work has to be redone or hidden cloud fees show up. The only way to keep the budget in check is by using milestone reviews and variance tracking, so actual spend is matched against forecasts before it runs out of control.
Check our Smart Ways to Lower Ecommerce Infrastructure Costs to see how to reduce cloud bills without sacrificing performance.
Execution phase
What’s worth noting during this phase is how pieces, such as discovery, transformation, infrastructure setup, and others, play out together. Plans meet live systems, and that’s often when overlooked details surface under real load.
Perform discovery and system audits
A migration only succeeds if you know exactly what you’re moving and leave behind the redundant or inefficient parts. For example, in a telecom project migration, our team audited the system to identify hidden custom files and deprecated fields during discovery. By cleaning them upfront, we avoided what could have become major setbacks later on. Static code analysis with SonarQube revealed dependencies buried deep in the system, showing why audits must go beyond field names.
A strong discovery phase catalogs all data sources, identifies environment drifts between test and production, and documents how data behaves inside workflows, not just how it looks in the schema.
Execute data transformation and mapping
In a global jewelry retail migration, loyalty programs broke when regional codes didn’t align: “TR” vs “TUR” meant discounts were misapplied across markets. That failure illustrates a larger point: transformation is not only technical restructuring but a test of semantic accuracy.
Best practices include checking for hardcoded values in legacy systems, surfacing runtime-derived fields, and validating categories that don’t map one-to-one. Real historical scenarios, not just synthetic data, are a reliable way to test these mappings.
Set up migration tools and infrastructure
Some projects rely on ETL platforms like Talend or Informatica, others benefit from tailored scripts. However, a robust setup goes beyond the core migration tool.
It should provide immutable snapshots for rollback and monitoring dashboards to catch issues like duplicate rates or orphaned records. In cloud environments, tuning may also be required, for example, indexing adjustments to offset distributed query slowdowns. These measures form the safety net before cutover begins.
Run comprehensive testing and validation
A quick reminder — pilots tend to reveal what production shouldn’t have to.
-
1
Conduct pilot migrations
Using real-world data, including edge cases, such as null fields, oversized records, or conflicting IDs.
-
2
Test integrations
Like middleware and APIs to catch mismatches early.
-
3
Validate referential integrity
By enforcing strict load orders (e.g., categories before products) and checking for orphaned records.
-
4
Run load and stress tests
With tools such as JMeter or Locust to simulate production conditions and detect performance degradation.
-
5
Plan iterative testing
To refine data mappings and uncover hidden dependencies before scaling up.
Conduct parallel operation where needed
Running old and new systems in parallel can lower risk, but it creates its own sync problems that put data integrity at stake. One system might capture updates the other misses, like an address change or a password reset. And if real-time sync isn’t set up properly, or it breaks under heavy load, those gaps only get worse.
The critical checks are straightforward:
- Are both systems writable during coexistence?
- What is the lag between updates?
- Can users place orders or change records in both environments?
Clear answers to these questions determine whether parallel operation stabilizes a migration or creates new points of failure.
Execute cutover and decommission legacy systems
The cleanest tests don’t guarantee stability under live traffic. A financial services migration proved this when URL misrouting caused integrations to fail during cutover. Because the legacy system was briefly left running, the issue was caught before it spread downstream.
Final cutover must include strict consistency checks across entities like orders, pricing, and inventory. Rollback ownership should be clearly defined, and decommissioning should never happen until snapshots are verified. These steps close the execution phase without leaving blind spots.
Download our Integration-Ready Ecommerce Whitepaper to see practical approaches for building smooth connections across platforms.
Post-migration validation
Post-migration validation often brings small but telling nuances, like edge cases that slip through standard tests, anomalies visible only under load, or feedback that exposes details logs don’t catch.
Confirm accuracy of complex edge cases
Synthetic QA scripts rarely hit the scenarios that cause real-world trouble. In a beauty company migration, loyalty points broke when a shopper added products before a promotion became active — a sequence never covered in standard tests.
The solution is to build test personas from anonymized behavior logs, replay their histories in the new system, and check the results against the baseline. Automating the flows with tools like Postman collections, Selenium scripts, or Groovy extensions makes the checks repeatable at scale.
Detect anomalies and unexpected behaviors in live operations
Even the most thorough UAT can’t replicate production. That’s why observability is critical in the first weeks post-cutover. For example, Expert Soft’s team was able to find schema mismatches in Kafka payloads during high-volume exports, visible only through embedded metrics and dashboards.
Without anomaly detection, those errors might stay unnoticed for weeks. The safeguard is to watch early warning signs, such as duplicate orders, missing profile data, rising support tickets, or sync delays, and set up real-time alerts to catch them quickly.
Capture user feedback to confirm usability and trust in data accuracy
Not every problem shows up in logs. Frontline business teams are usually the first to spot small inconsistencies. For example, a shipping option missing in one region, taxes tagged wrong on a bundle, or pricing that just doesn’t add up.
It pays to run structured UAT with domain owners and keep feedback easy to share: a Slack channel, error flags, or a dedicated ticket category can make a big difference. In the end, it’s the mix of automated checks and human eyes that builds real confidence in the migrated data.
With these core steps in place, you have a checklist that not only guides your migration but also helps you sidestep the most common migration mistakes.
How This Checklist Safeguards the Migration Process
A structured checklist helps teams stay on track and avoid the small mistakes that can quietly derail a migration. Here are some of the most common ones and how to keep them in check.
-

Incomplete data inventory
Discovery often stops at field names while business rules stay undocumented. This leads to broken CMS logic, duplicated or missing promotions, and mismanaged campaign priorities. A full data inventory step in the checklist makes sure those rules are captured before they slip through.
-
Loss of referential integrity
The checklist calls for strict loading order: categories, then products, promotions, and only after that orders. Skipping it in bulk loads easily breaks relationships: orders start referencing missing customers, or product IDs collide across regions, leaving orphaned records and unreliable analytics.
-

Parallel systems drift
During coexistence, the checklist points to one master source of truth as a non-negotiable. Without it, old and new systems drift apart—customer profiles lose consistency, loyalty balances misalign, and sync conflicts multiply.
-

Performance degradation in cloud migration
Processes that work on-premise slow down in cloud environments due to latency and unoptimized queries. That means failed nightly jobs, order delays, and customer dissatisfaction. The checklist doesn’t treat “lift and shift” as enough, it requires cloud readiness to be validated with stress tests and query reviews before the switch.
-

Weak post-migration monitoring
Clean logs don’t confirm correctness. Issues like duplicate orders, incorrect balances, and compliance gaps often appear only under live traffic. The checklist includes monitoring and validation steps to confirm correctness beyond what logs reveal.
By addressing these nuances, the checklist safeguards migration outcomes and ensures systems remain accurate, compliant, and stable under real-world conditions.
To Sum Up
A migration checklist is not paperwork for the sake of process. It is the mechanism that prevents outages, compliance breaches, and runaway costs. By defining scope, selecting the right strategy, planning rollback, and validating under real conditions, enterprises give themselves a controlled path through one of the highest-risk IT initiatives.
If you’re planning a migration and want to pressure-test your approach, our team at Expert Soft is always open to a conversation.
FAQ
-
What are the steps for the data migration process?
The key steps for successful data migration usually include defining scope and strategy, aligning technical and business teams, prepping and configuring systems and data, running pilots and stress tests, and handling cutover with post-migration checks. Each stage cuts risk and helps keep data quality solid in the long run.
-
What to consider when migrating data?
When migrating data, the main things to weigh are regulatory requirements, rollback and recovery options, operational and performance risks, and data consistency across systems. If you miss any of these, you risk both compliance issues and broken operations.
-
How do you validate data migration?
We validate successful migrations by running pilots with real historical data, stress testing in production-like environments, and fine-tuning mappings step by step. After go-live, we watch for anomalies with real-time monitoring and collect structured feedback from business users. In the end, it’s the mix of automated checks and human review that builds real trust in the migrated systems and allows to refine future migration processes.
-
How to audit data migration?
Effective audits involve cataloging all data sources, documenting transformations, and maintaining immutable logs for every change. Audit trails support compliance reporting, while behavioral inventories and dependency reviews surface hidden rules. Comparing pre- and post-migration snapshots provides evidence of accuracy, completeness, and regulatory alignment.
When advising enterprises on platform modernization, Alex Bolshakova, Chief Strategist for Ecommerce Solutions at Expert Soft, emphasizes the importance of a structured data migration checklist to reduce risk and ensure business continuity during transformation.
New articles

See more

See more

See more

See more

See more
