")
Simplifying Service Maintenance for an International Financial Intelligence Provider
Splitting one overloaded API into three focused services to separate business-specific logic and reduce cross-business impact.
Quick Insights




Client
The client is an international financial intelligence provider that delivers research, market insights, and company-related analytical content through digital platforms used by financial professionals, investors, and enterprises.
Client Need
The client’s digital products needed a reliable way to search and retrieve company-related research content, including analytical documents, news-like materials, and associated metadata. This functionality was handled by a shared back-end Research Service that worked as an API layer over the search engine.
Over time, the same service started supporting several business lines, each with its own filters, fields, response formats, and search behavior. As these differences accumulated, business-specific logic became mixed inside one codebase, making the service harder to maintain and changes riskier.
The client needed to split the shared service into focused services with clearer boundaries, while preserving stable access to research content for downstream systems.
Technical Considerations
The split had to preserve core search capabilities while removing business-specific branching from the shared service. This required several technical considerations:
- Keep the API role focused
The service remained responsible for back-end document search and retrieval, without taking ownership of front-end logic. - Separate business-specific behavior
Each new service needed its own filters, fields, response formats, and query rules aligned with its business line. - Avoid carrying over unnecessary legacy logic
Only relevant functionality had to be extracted into each new service, rather than duplicating the overloaded original codebase. - Preserve predictable search behavior
Query logic, filters, sorting, and result retrieval had to be adapted to what the search engine could support reliably. - Keep API behavior predictable for consumers
Error handling, pagination, and result navigation had to remain consistent and clear across the new services.
Given these constraints, the task required more than decomposing one service into three copies. Expert Soft had to reshape the API layer, so each service could evolve independently while still providing reliable search behavior.
Solution
With proven practical experience in back-end development services, Expert Soft split the overloaded Research Service into three independent but structurally similar services, each aligned with a separate business line. The goal was not to duplicate the original service three times, but to remove accumulated cross-business complexity and give each new service a cleaner foundation for future changes.
Splitting the Shared Research Service
Expert Soft separated the original service into three focused APIs, each with its own business-specific behavior while preserving a comparable core structure.
The split included several key steps:
This split created cleaner service boundaries, but it also required several supporting improvements to make document retrieval, API responses, and client navigation predictable across the new services.
Supporting Large Result Set Retrieval
One of the supporting improvements focused on making large research result sets easier to retrieve. Some users and downstream systems needed to work with thousands of documents, but the previous pagination approach was reliable only for smaller result sets.
At the technical level, the new services worked with ElasticSearch, where standard pagination could not reliably retrieve documents beyond a certain threshold. To solve this, Expert Soft introduced a separate bulk retrieval endpoint based on token-style iteration:
- The search engine returns a position token that identifies the current place in the result set.
- The service passes this token to the client without storing it internally.
- The client sends the token in the next request to retrieve the following batch of documents.
- The same filters and sorting remain available so clients can retrieve large result sets without losing the search combinations they used before.
- The results remain consistently ordered, so the system can move through larger document sets predictably.
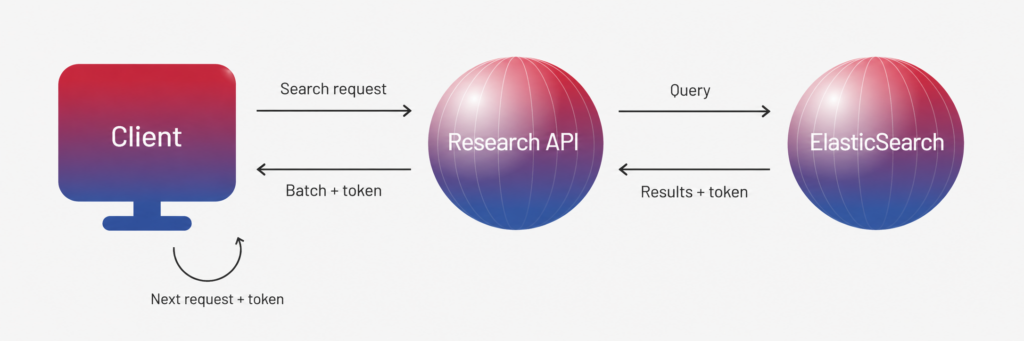
This approach allowed clients to retrieve thousands of documents without pushing ElasticSearch beyond pagination limits, making bulk document access more stable for users and downstream systems.
Standardizing API Error Handling
Another supporting improvement focused on making API behavior more predictable for client applications. Since the original service was split into three APIs, error responses had to remain consistent, clear, and easy to process across all of them.
Expert Soft introduced a unified error handling approach where each failure response followed the same structure:
- HTTP status code to indicate the type of failure.
- Structured error identifier to help client applications recognize and handle the issue.
- Human-readable description to make troubleshooting easier for developers and support teams.
The mechanism was implemented through centralized exception handling in Spring. This allowed different exception types to be processed through a common path and returned in a consistent format, reducing ambiguous responses and making the new services easier to integrate with.
Together, these changes gave each new research API a cleaner operating model. Business-specific logic was separated, larger document sets could be retrieved without hitting pagination limits, and client applications received errors in a predictable format.
Results





Technologies
Java, Spring Boot, ElasticSearch, REST API, Spring Framework
Conclusion
Expert Soft helped the client turn an overloaded research API into three focused services that better matched the needs of separate business lines.
Instead of keeping business-specific filters, fields, and response logic inside one shared service, the new structure gave each API its own cleaner operating space. Combined with token-based bulk retrieval and unified error handling, this made research content easier to retrieve, client integrations more predictable, and future service changes less risky.
