
Building Flexible Data Delivery Management for a Global Financial Data and Research Provider
Shifting from a hardcoded setup to configurable delivery management with stable processing for large data volumes.
Quick Insights




Client
The client is a global financial data and research provider that delivers market data, research content, and structured financial datasets to enterprise customers through digital platforms and client-specific data feeds.
Client Need
The client’s platform helps enterprise customers receive structured financial data in the formats, scope, and frequency they need for internal analytics and decision-making.
However, part of the existing data delivery flow gave customers limited control over feed configuration. Changes to data scope, filters, delivery format, or frequency were mostly handled internally, which made customers dependent on technical specialists even for routine adjustments. As customer-specific requirements grew, this model created operational overhead, slowed down updates, and made the process harder to scale.
The client needed a more flexible and manageable data delivery flow that would let customer-specific configurations evolve more easily while keeping the existing delivery behavior stable for enterprise users.
Technical Specifics
The client’s data delivery platform was not a single isolated application. It combined a long-running legacy component with a broader service landscape responsible for data preparation, configuration, event handling, and customer-specific delivery. The main challenge was to modernize one critical part of this flow without disrupting how enterprise customers already received their data.
The solution had to account for several technical specifics:
- Legacy generation flow
A JBoss-based application handled scheduled data generation, transformation, and file preparation. - Broader service ecosystem
The legacy component worked alongside related services and microservices, so the new flow had to fit the existing environment. - Existing customer delivery expectations
The updated flow had to preserve the expected output format, file structure, and delivery behavior. - Limited transformation documentation
Transformation rules were not fully documented, so behavior had to be validated against historical outputs. - Indirect access to indexed data
The new flow received indexed data through an internal service instead of querying the search layer directly. - Compatibility with existing delivery infrastructure
Generated files still had to be placed into client-specific locations used by the current delivery process.
Given these constraints, the task was not a simple service rewrite. Expert Soft had to preserve the business-critical delivery behavior of the legacy flow while making the generation logic clearer, more maintainable, and easier to evolve inside the broader platform architecture.
Solution
As part of legacy migration services, Expert Soft supported the client’s transition from a legacy data delivery flow to a microservice-based implementation with a React front-end. The new implementation consumes data from upstream systems, works with final aggregated tables, and allows customer-specific delivery settings to be managed through a customer-facing interface instead of relying mainly on internal technical changes.
Through this flow, customers can define key delivery parameters during onboarding and adjust them later when their needs change:
- Data scope and filters to define which datasets should be included.
- Delivery format to match how data is consumed in the customer’s internal systems.
- Delivery frequency, such as daily, weekly, or monthly schedules.
- Configuration updates to add new delivery setups or adjust existing ones.
This created a clearer foundation for configurable data delivery while keeping the existing customer experience stable. Enterprise customers could continue receiving files through the established delivery flow, while the platform gained a more maintainable structure for future customer-specific changes.
Rebuilding the Legacy Generation Flow
To support the migration, Expert Soft had to adapt a critical part of the existing delivery flow: scheduled data generation, transformation, and file preparation. The goal was to move this logic into the new setup while preserving the file structure and delivery behavior enterprise customers already expected.
In the legacy flow, a scheduled job retrieved data, transformed it, and placed customer-specific files into predefined delivery locations. To reproduce this behavior in the new architecture, Expert Soft implemented a separate Spring Boot service.
The main challenge was the lack of documented transformation rules. To validate the new service, we compared generated files with historical outputs from the legacy flow and documented the data flow and transformation logic along the way.
The resulting service handled the flow in several steps:
- Data retrieval through an internal service
The service requested indexed data from an internal API for specific filters and time windows, instead of querying the search layer directly. - Transformation into the expected structure
The retrieved data was transformed to match the format already used in customer delivery files. - XML file generation
The transformed data was converted into XML files required by the delivery process. - Delivery to customer-specific locations
Generated files were written to predefined customer directories on mounted storage, while retrieval, retention, and archival remained handled by existing systems.
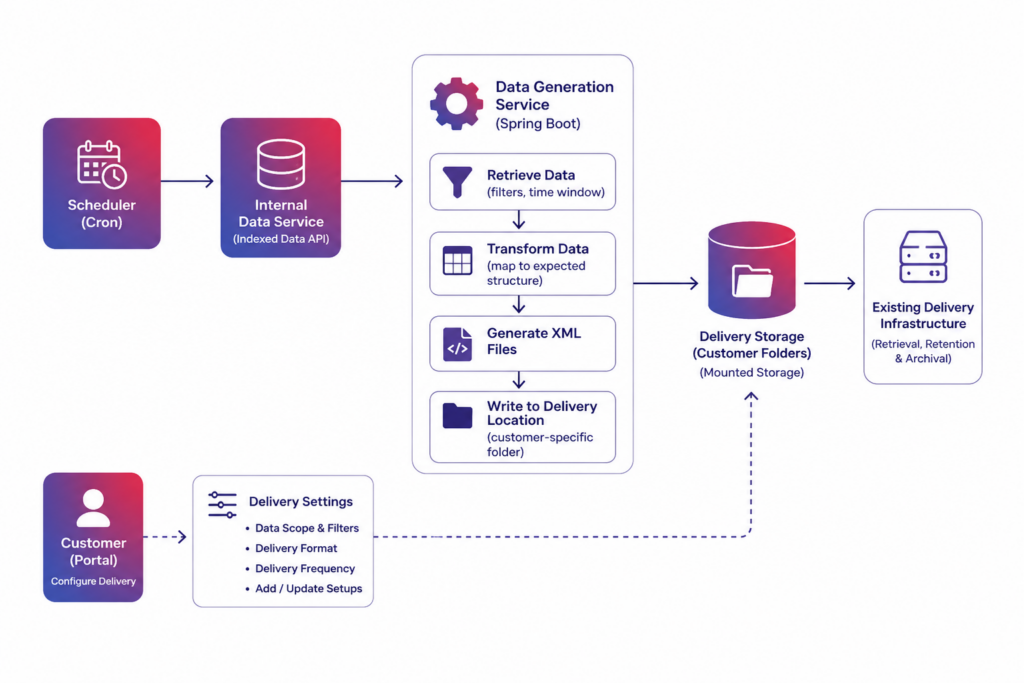
As part of this work, Expert Soft also documented the data flow and transformation logic, making the generation process easier to maintain and extend in the new architecture.
Stabilizing Microservices
In parallel with the migration, Expert Soft had to stabilize several related microservices that supported the broader data delivery flow. Some of them had grown beyond their original processing assumptions, while others needed stronger monitoring or more consistent event handling to work reliably in a larger microservice-based ecosystem.
Stabilizing Microservices



Results





Technologies
Java, Spring Boot, JBoss, Kafka, REST API, XML, JSON, React
Conclusion
Expert Soft helped the client modernize a business-critical data delivery flow without disrupting how enterprise customers received their files.
By moving legacy generation logic into a service-based setup, preserving expected delivery behavior, and stabilizing related microservices, the team created a stronger foundation for configurable customer-specific data delivery. The work also improved operational reliability through batch-based processing, monitoring coverage, and more consistent event handling across the surrounding service ecosystem.
