
Scaling Analytical Data Delivery for a “Big Three” Credit Rating Company
A custom data pipeline that keeps large volumes of data synchronized and ready for users to search, filter, and analyze.
Quick Insights




Client
The client is one of the “Big Three” credit rating companies offering research, analytics, and market data to investors, financial institutions, and enterprises worldwide. Its digital platforms serve complex analytical datasets through dashboards, search, and filtering tools.
Client Need
The client’s analytical portal had to enable users to view, search, and filter large volumes of analytical indicators without delays or outdated results. However, the existing data processing flow struggled to keep up: the source database contained over 60 million records, with millions more added daily.
The source database also stored a much broader set of analytical data, while the portal needed only a specific subset related to indexes. The client needed back-end web development services to create a dedicated serving layer for this data and keep it synchronized with source changes without relying on long-running scheduled jobs.
Data Processing Requirements
While the business goal was clear, the technical reality was more complex than moving data from one database to another. The solution had to work within several data processing requirements:
- preserve the source analytical database — Postgres — as the system where upstream data was written and maintained;
- move only index-related data into a dedicated MongoDB serving database for user-facing scenarios;
- transform relational source data into MongoDB documents suitable for search, filtering, and visualization;
- process frequent updates without relying on long-running scheduled batch jobs;
- support dynamic filtering by indicators, geographies, and time ranges;
- remain stable when processing very large data loads.
The main complexity was that the data in Postgres and MongoDB had different structures. In Postgres, one index could be built from several related tables. In MongoDB, the portal needed this information as one complete document, ready for search, filtering, and display. So the pipeline had to gather the right pieces of data, combine them correctly, and update the MongoDB document even when only one part of the source data changed.
Given these constraints, the task was not limited to synchronizing two databases. Expert Soft had to design a processing model that could assemble complete index documents from changing source data and serve them efficiently to the web application.
Solution
Expert Soft redesigned the data processing flow into a custom Kafka-based pipeline that keeps index data synchronized between Postgres and MongoDB. The solution captures source data changes, transforms them into complete MongoDB documents, and prepares them for fast search, filtering, and display in the analytical portal.
Solution Design
After evaluating these options, Expert Soft chose a custom processing approach instead of relying on out-of-the-box synchronization. This gave the team full control over data assembly, transformation logic, and optimization.
Solution Architecture
The solution was built as a connected data processing and serving flow.
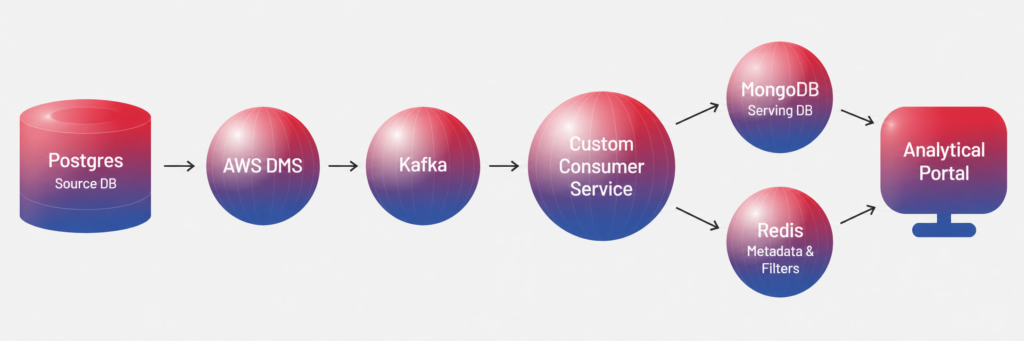
Each component had a clear role:
- Postgres remained the source database where upstream analytical data was written and maintained.
- AWS DMS tracked changes in selected Postgres tables and published them for further processing.
- Kafka acted as the messaging layer that delivered source data changes to the processing pipeline.
- Custom back-end consumer service processed Kafka events, applied transformation logic, and assembled complete index documents.
- MongoDB stored prepared index documents as a dedicated serving database for the portal.
- Redis cached metadata and valid filter combinations, such as indicators, geographies, and time ranges, so the portal could return meaningful filter options faster.
The team did not arrive at this architecture in one step. The pipeline went through several versions, with each stage addressing a specific limitation in data processing speed, message completeness, and system stability.
Architecture Evolution
The final architecture was reached gradually. The team started with a simpler scheduled ETL model, which was enough to move selected index data into MongoDB, but not strong enough for frequent high-volume updates. As data volumes grew and processing windows became harder to control, the solution had to evolve toward a more stable, event-driven model.
Version 1.0: Scheduled ETL
At the first stage, the synchronization flow was based on scheduled extraction. This approach was straightforward and gave the team a controlled way to move index-related data into MongoDB, but it was still tied to periodic batch processing.
The data flow included three main steps:
- Postgres stored the source analytical data, including both index-related information and a broader set of analytical records used by other parts of the system.
- A scheduled cron job triggered the extraction process, launching the ETL flow at defined intervals instead of reacting to each source data change as it happened.
- The ETL service collected and transformed the required index data, then wrote the prepared structure into MongoDB for the portal to use.
This version helped separate index-related data from the larger source database, but its limitations became clear as update volumes increased.
Large uploads took too long to process, and because the flow depended on scheduled execution, updates could not be reflected as soon as the source data changed. Over time, this made the cron-based model too rigid for frequent high-volume updates and created the need for a more responsive processing approach.
Version 2.0: Kafka-based processing
To move beyond the limitations of scheduled ETL, the solution was redesigned around Kafka-based processing. Instead of waiting for a cron job to trigger the next large extraction, the system could now react to source data changes as they were published.
The updated data flow included several key steps:
- Postgres remained the source database, where upstream systems continued to write and maintain analytical data.
- A change-capturing service published database changes to Kafka, allowing the pipeline to receive updates as events rather than waiting for the next scheduled batch run.
- Kafka delivered change events to consumer services, creating a continuous message-driven flow between the source database and the processing layer.
- Consumer services processed Kafka events and applied ETL logic, assembling index documents and writing the updated structures into MongoDB.
This version moved the pipeline from scheduled batch processing to a more responsive event-driven flow. It reduced dependency on cron jobs and allowed updates to be processed closer to the moment they appeared in the source database.
Still, the approach had limitations. Kafka events did not always contain enough context to build a complete MongoDB document, and one business-level update could arrive as several technical events.
As a result, the back-end service processing Kafka messages sometimes had to request missing data from Postgres before updating MongoDB. This slowed down processing and made the pipeline less stable under large update volumes.
Version 2.1: Enriched Kafka messages
To address the limitations of partial Kafka events, the message structure was improved. Instead of sending only changed fragments, Kafka messages were enriched with the complete data set required to build or update an index document in MongoDB.
The updated data flow became more self-sufficient:
- Postgres remained the source database, where analytical data continued to be created and updated by upstream systems.
- The change-capturing layer published enriched events to Kafka, adding the context needed for further processing.
- Kafka delivered complete update messages to the back-end processing service, reducing dependency on additional source database reads.
- The back-end service assembled and updated MongoDB documents using the data already available in the message.
This became the final and stable version of the pipeline. By making Kafka messages self-sufficient, the system no longer had to request missing data from Postgres before updating MongoDB. This allowed the pipeline to process large data loads more predictably and handle hundreds of millions of records within approximately one hour.
For the business, the architecture created a controlled processing window, ensuring that large updates could be completed within an acceptable timeframe instead of accumulating into long-running backlogs.
Serving Processed Data to the Portal
The pipeline does more than synchronize data between Postgres and MongoDB. It prepares index data in a structure that the portal could use efficiently for dashboards, search, and filtering.



This makes the processed data directly useful for users, supporting faster filtering and helping the portal show only data combinations that actually existed in the system.
Results





Technologies
Java, Postgres, MongoDB, Kafka, AWS DMS, Redis, GraphQL, Kubernetes
Conclusion
By evolving the synchronization flow from scheduled ETL to a stable Kafka-based pipeline, Expert Soft helped the client turn high-volume index data processing into a more predictable and reliable operation.
The final architecture separated the large source database from the user-facing data layer, improved how index documents were assembled, and made analytical data easier to search, filter, and display in the portal.
