How to Build a Robust Data Migration Plan: Key Steps & Tips

For a tech leader, a data migration cutover is a test of execution, trust, and control. A missed date can stall launches, broken records can undermine customer trust, and gaps in traceability can trigger compliance questions. The risks are measurable: many firms reported losses of over $5 million each year from poor data quality.
With this number in mind, the role of a system migration plan becomes clear, as even small technical oversights can create major setbacks. Knowing which steps to prioritize and where risks may surface is what makes the difference between a smooth transition and a costly failure. Our aim in this guide is to walk through the building blocks of a reliable migration plan that keeps risks visible, timelines realistic, and business operations uninterrupted.
Quick Tips for Busy People
When you’re putting a migration plan together, focus less on “filling out a template” and more on what will actually keep the project safe and predictable:
- Define the boundaries. Be clear about scope, success criteria, and ownership so there’s no debate halfway through.
- Know your data. Different data types have different pain points, so plan for those quirks up front.
- Pick the right path. Document why you chose phased, parallel, or hybrid so the implications are transparent.
- Line up people and process. Make sure roles, communication, and fallback options are planned before anyone touches production.
- Keep validation alive. Build in monitoring and checkpoints so you catch issues early instead of after go-live.
Each point below highlights a step that keeps the migration controlled and the data intact.
Key Elements Every Reliable Data Migration Plan Needs
A credible system migration project plan consists of elements that safeguard data integrity and raise overall quality. The points below show what improves your odds of success.
-

Scope & objectives
Understanding what moves and why, whether it's cloud adoption, a platform upgrade, or consolidation, and establishing how success will be measured. Capture volumes, dependencies, and compliance regimes, such as GDPR or HIPAA.
-

Risk model
Includes identification of possible failure modes, such as data corruption, loss of business logic, or operational disruptions, and pairing each risk with a clear mitigation strategy. This can be phased execution to reduce corruption risk, logic validation to prevent business rule loss, or defined rollback procedures for no-rollback scenarios.
-

Data inventory & mapping
Auditing of all data sources, including hidden semantics and referential integrity. For this, create mapping matrices that document field names along with their meanings, value ranges, and edge cases, covering issues like fallback values or hardcoded logic, so hidden gaps don’t compromise integrity later.
-

People, tools, timeline
Requires assigning roles across DBAs, domain experts, security, and QA. Support the team with ETL/ELT pipelines and observability tools, and define milestones with decision gates that account for coexistence drift.
-

Validation framework
Testing beyond structure: use unit and integration tests, UAT with real examples, and load tests. Track KPIs such as duplicates, orphaned references, or sync latency to confirm that integrity is intact.
-

Change management
This part defines how communication will flow across teams, how training will prepare users, how activities will be timed for low-traffic windows, and how incident playbooks will guide responses. Migration touches every department, so alignment is key.
-

Budget & controls
Planning for tool costs, environments, rework, and cloud fees. Always leave a buffer for the unknowns.
If you’re planning data migration, talk to us about your scenario and get practical guidance for building a reliable plan.
Adapting Migration Plans to the Realities of Your Data
You’re never just moving “data” in the abstract. What actually travels are files, databases, and application states, each with its own quirks and failure patterns. A reliable plan has to adjust to those differences.
Storage migration (files, objects)
With this type of data, the main challenges lie in scale, consistency, and minimizing downtime during bulk data transfers. Throughput, checksums, and permissions remain critical, with corruption risks increasing as volumes grow.
Network conditions add another layer: what runs smoothly on a LAN may fail over a WAN. Transfer data in chunks, plan for retries, and validate checksums throughout. Don’t overlook metadata: access logs, retention rules, and lifecycle policies must be re-validated at the destination to avoid hidden failures.
Database migration (relational/NoSQL)
Databases carry complexity in schemas, indexes, triggers, and stored routines. Each vendor has specifics that tend to surface during version upgrades or cloud-to-cloud moves, especially when backward compatibility is limited.
Load order matters as well: miss a foreign-key dependency and you end up with orphan records. Even fields with the same name across systems don’t always mean the same thing, so harmonizing code sets and enums is essential.
Application data migration (profiles, configs, state)
Applications carry the closest link to business behavior. Configurations, overrides, and embedded rules shape how the system functions for both users and internal processes. During coexistence, stateful data, such as profiles or loyalty balances, can drift unless a single source of truth is enforced.
For example, when a large beauty and retail platform ran a legacy site and a new front-end in parallel, unsynchronized profile updates caused inconsistent personalization and loyalty statuses. To avoid this, the migration plan should account for middleware and the “temporary” patches that often accumulate over the years, deciding early which ones to migrate deliberately and which to retire with a clear exit strategy.
Scalable retrieval in complex stacks is never straightforward. Our whitepaper explores proven strategies and approaches you can apply in practice.
Download the whitepaperMigration Strategy as The Core of Your Migration Plan
In a platform migration or upgrade, no strategy runs in its pure form, but understanding the core approaches is the only way to navigate the mix you’ll inevitably face.
In practice, large ecommerce and enterprise leaders face these strategies every day, and the right fit often depends on how their business is structured. Here are a couple of examples:
-
1
Multi-region marketplace
With varying tax rules, payment providers, or fulfillment systems, a phased migration lets leaders move region by region, limiting risk while keeping core markets steady.
-
2
Always-on enterprise:
For businesses that can’t tolerate downtime, for example, during peak retail seasons, a parallel strategy allows old and new systems to run together until the new one proves stable.
-
3
Complex legacy stack:
Enterprises with layered ERP, PIM, and loyalty systems often adopt a hybrid approach, shifting individual services first while the old core continues to carry the load.
Choosing a strategy, understanding your data — all these activities are essential on the very first steps of migration, when nothing is actually moved. What else should be considered in the preparation phase? Let’s consider.
Preparation as the First Step of the Migration Plan
Preparation is what makes coordination easier and execution smoother, helping the migration plan run without obstacles, especially in integration-ready ecommerce environments where multiple platforms, payment providers, and data streams converge. The groundwork comes down to a few essentials:
-
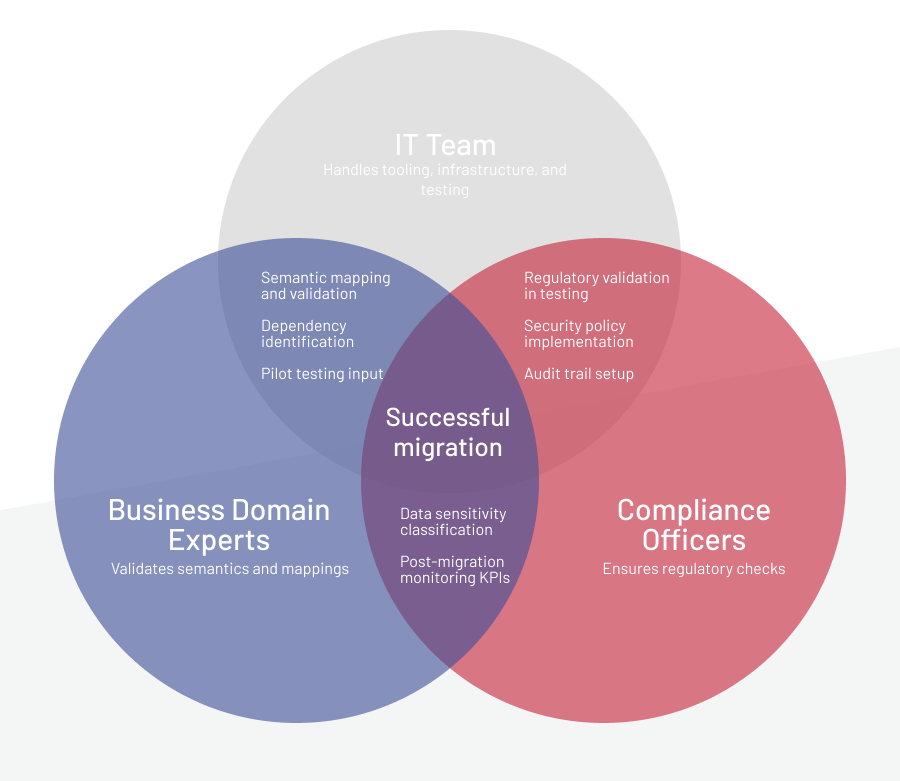
Align stakeholders
Bring in the right mix of people: IT specialists, domain experts, compliance officers, and end-users to double-check the details, flag risks, and point out how changes affect day-to-day work. Be clear about who owns the mapping and validation tasks. And don’t forget training and open communication to smooth the transition and keep pushback low.
-

Risk planning
Expect bumps like data glitches, workflow hiccups, or compliance slip-ups. Protect yourself with safeguards: take immutable snapshots, design steps you can rerun, and keep partial rollbacks ready if things go wrong. Keep systems in sync with solid reconciliation checks, and make sure GDPR and HIPAA reviews are part of your testing so nothing leaks through.
-

Change management
Make sure everyone’s on the same page with a simple communication plan: from early planning all the way past go-live. Time your cutover for off-peak hours to avoid disruption and have a backup ready in case orders, payments, or fulfillment hit a snag. Give your team hands-on training to cut down mistakes and set up a support crew to quickly fix any issues after launch.
-

Document and govern
Keep all dictionaries, mappings, and decision logs in one place so everyone works from the same playbook. Set clear KPIs for after go-live, and keep monitoring well past the first week to spot and fix issues early.
Now, the focus shifts to execution: the phases that turn a migration plan into a working reality.
Steps of a Robust Migration Plan
A migration plan is a staged progression where each step reduces uncertainty and protects data integrity. The steps below outline how to build a plan that keeps both systems and business operations stable.
Step 1: Discovery and audits
Start by inventorying your data sources and how they behave. Don’t rely on ERDs alone — pull real samples. This is where legacy logic surfaces: hardcoded defaults, regional fallbacks, or conditional pricing rules that stay undocumented until execution.
Static analysis tools like SonarQube are invaluable here. In a telecom ecommerce migration project, it helped us uncover deprecated components and fix issues before cutover. Systematic environment comparisons are also essential, as drift between test and production has disrupted many migrations. Document these findings early, as they form the foundation for the rest of the plan.
-

Pro tip:
The more complete your discovery, the fewer blind spots in later phases. Treat undocumented defaults and drift as high-risk items, not footnotes.
Step 2: Transformation and mapping
Once the data inventory is complete, the next task is reshaping it for the target model without losing meaning. Fields that appear identical can behave differently. For example, a “tier” may be computed in one system and stored in another. Small inconsistencies in code sets can quickly escalate into costly issues.
A global replatform for a jewelry brand highlighted the risk: one system used “TR” for Turkey, another “TUR.” The mismatch triggered pricing errors and incorrect reward allocations until translation rules and documentation brought consistency.
-

Pro tip:
Lock down clear rules for hardcoded values and derived fields. If you skip this, hidden ambiguities will sneak into the migration and resurface later as production errors.
Step 3: Tooling and infrastructure setup
A solid migration relies on the right tools for extraction, transformation, and loading (ETL). Based on data complexity, you can benefit from specific ETL/ELT platforms, such as Talend or Informatica, or rely on custom scripts.
When setting up infrastructure for testing, include sandbox environments that mirror production as closely as possible to catch environment-specific issues. Jobs that run fine on a fast LAN can break under cloud latency, and realistic testing helps avoid nasty surprises. Build resilience into your setup: use immutable snapshots and database backups at every stage so you can roll back safely, and design jobs to be rerunnable to keep reprocessing costs down.
-

Pro tip:
Make visibility part of the plan from day one. Dashboards should flag duplicates, orphaned records, or sync delays, with alerts going straight to the migration team so problems get fixed before they snowball.
Step 4: Testing and validation
Start with pilot migrations using production-like datasets, including edge cases, such as null values, oversized payloads, and colliding IDs. From there, design the load sequence to preserve referential integrity: categories first, then products, promotions, and finally orders.
Once the data is in place, validate stability under real-world conditions with load and stress tests in production-like environments using tools, such as JMeter or Locust. That way, you can spot bottlenecks from clunky queries or heavy batch jobs. Keep testing in cycles: refine mappings, tweak pipelines, and uncover hidden dependencies until you’re confident the system can scale.
-
Pro tip:
Keep testing in cycles: refine mappings, tweak pipelines, and uncover hidden dependencies until you’re confident the system can scale.
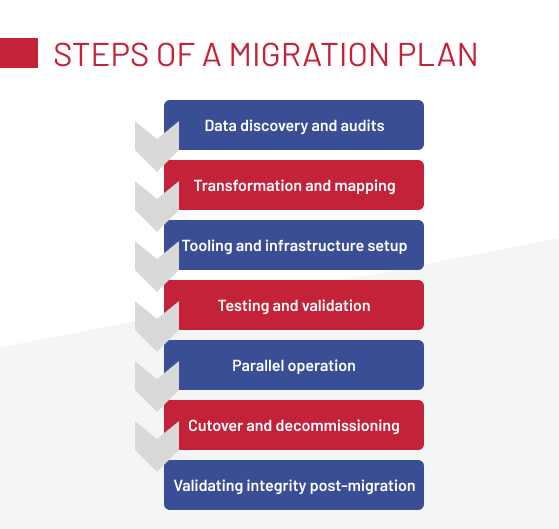
Step 5: Parallel operation
During a migration at a large beauty and retail platform, both a legacy JSP site and a new Spartacus front-end were running in parallel. Customer profile updates weren’t always propagated across systems, which led to mismatched personalization and loyalty balances. This example highlights the hidden risks of coexistence: one system may capture changes that never reach the other, real-time sync can break under load, and without a single source of truth, conflicts in customer or inventory data quickly accumulate.
To reduce these risks, treat parallel runs as temporary and tightly controlled. Monitor update lag, reconcile discrepancies early, and define strict rules about where users can place orders or update profiles.
-
Pro tip:
Coexistence only works when discipline is absolute. If it can’t be enforced, shorten the overlap and increase validation frequency to avoid drift.
Step 6: Cutover and decommissioning
During one infrastructure shift for a leading credit rating agency, routing quirks only became visible once production traffic hit. Because a fallback environment had been planned, those issues were contained. That’s the point of this step: by cutover, scripts should handle the switch, but only if they’ve been rehearsed.
Triple-check any process that mutates records permanently, and keep the legacy environment accessible for a bounded fallback window. That safety net reduces the blast radius if defects appear under live traffic.
-
Pro tip:
Success at cutover depends on rehearsal. Run scripts repeatedly in production-like conditions and don’t decommission legacy systems until rollback paths are proven.
Step 7: Validating integrity post-migration
A clean log isn’t proof of success, so integrity has to be checked under real use. Use a structured validation matrix to cover:
- Fields and records: nulls, ranges, referential integrity
- Business rules and behavior: discounts, loyalty balances, returns
- UI and operations: prices, addresses, order flows
Edge-case simulations (e.g., promotions overlapping with returns) and production monitoring (dashboards, anomaly detection) are key.
-
Pro tip:
Keep domain experts in review, as they’ll catch functional misfits automation misses.
This whitepaper shows how enterprises can reduce expenses without putting stability at risk.
Download the whitepaperWhat to Watch for During Migration
Data moves often expose less obvious data migration nuances that can corrupt records or disrupt processes if missed. The following aspects deserve close attention:
-
Semantic field mismatches
Fields may share names across systems but encode different values or business rules. Without mapping matrices, domain-owner review, and sample-based testing, these discrepancies distort logic once in production.
-
Referential integrity failures
Incorrect load order or non-unique identifiers can leave records orphaned. Enforcing sequencing, guaranteeing global uniqueness, and running pre-flight checks are critical safeguards.
-
Bidirectional update conflicts
When legacy and target systems both write to the same domain, data diverges. Establish a single source of truth, sync in near real time, and reconcile regularly with logs and counters.
-
Undocumented legacy customizations
Hardcoded overrides and ad-hoc patches often clash with vendor logic in the new environment. Conducting an upfront inventory and refactoring critical customizations reduces the risk of failure.
-

Rollback gaps
Missing snapshots or recovery paths let defects propagate unchecked. Immutable checkpoints and tagged batches (source, timestamp, tool version) ensure recovery remains possible.
Addressing these risks during execution is essential, and a structured checklist helps ensure they’re managed consistently.
Data Migration Plan Checklist
The checklist is a quick way to see what needs to be done and accounted for. Use the points below to challenge your plan before execution:
- Define scope & success: sources, goals, metrics, legal constraints.
- Account for risks & mitigations: named failure modes, rollback at each major phase.
- Map inventory & semantics: dictionaries, translations for code sets, relationship maps.
- Assign people & tools: roles, decision owners, ETL/ELT, observability, budget buffers.
- Prepare environments: production-like sandboxes, snapshots, and rerunnable pipelines.
- Run pilots: real data, edge cases, integration, and load tests.
- Execute with control: enforced load order, uniqueness, automated checks and alerts.
- Validate outcomes: UAT, drift/duplicate monitoring, anomaly detection.
- Cut over and follow up: fallback plan, extended monitoring, governance updates and lessons learned.
Even with the best preparation, no migration unfolds exactly as planned. Systems behave differently under load, hidden logic surfaces late, and organizational alignment is always tested under pressure. That’s why a plan has to combine technical guardrails with practical governance, so the team isn’t reacting ad hoc when issues appear.
At Expert Soft, we’ve seen how naming risks early, assigning owners, and validating every stage can turn migration into a predictable process. If you’d like to explore this further, our team is always open to a conversation.
Andreas Kozachenko, Head of Technology Strategy and Solutions at Expert Soft, has supported numerous complex system migrations. His strategic expertise ensures every critical step is accounted for, helping teams avoid surprises during data migration projects.
New articles

See more

See more

See more

See more

See more
